获取详情页处调试问题
老师好,我刚开始学,学到提取详情页信息那里,但是调试无法在断点处停下来,直接就结束了,而且调试信息中间有Error,最后结果却是返回0。有点疑惑,请老师指教。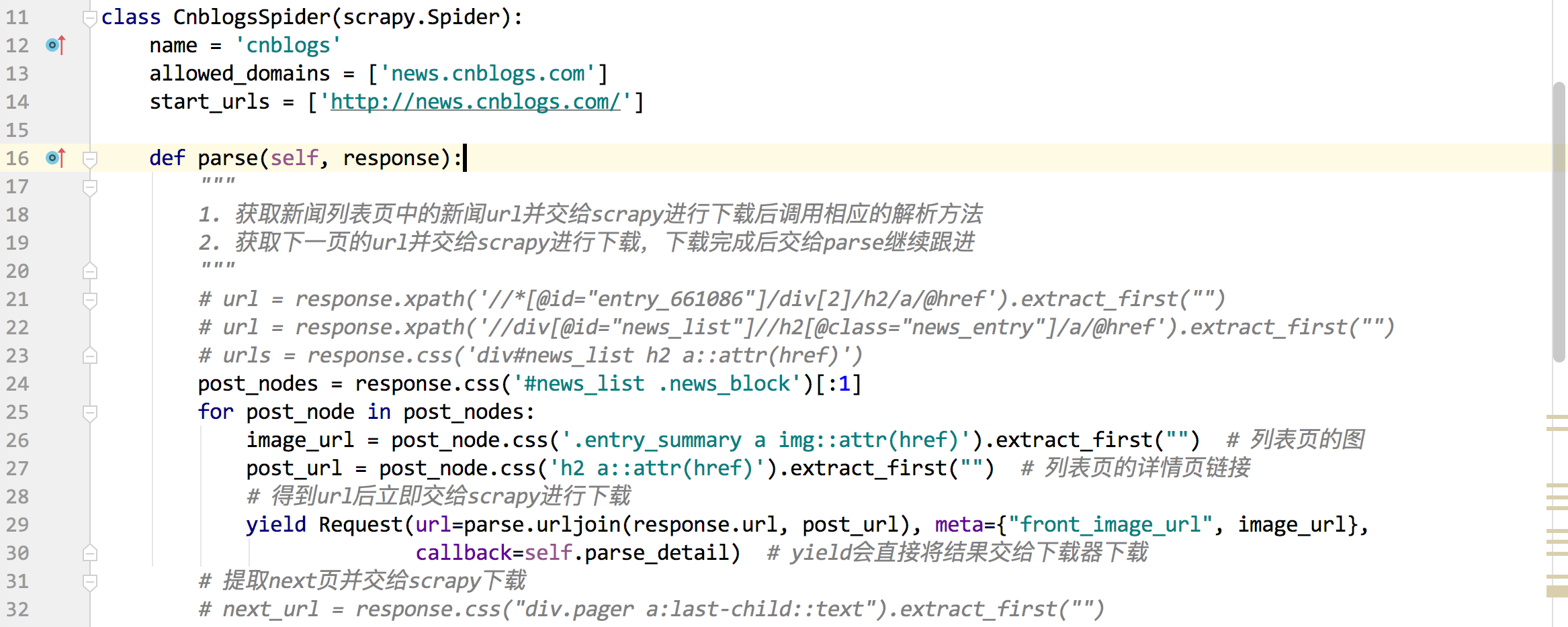
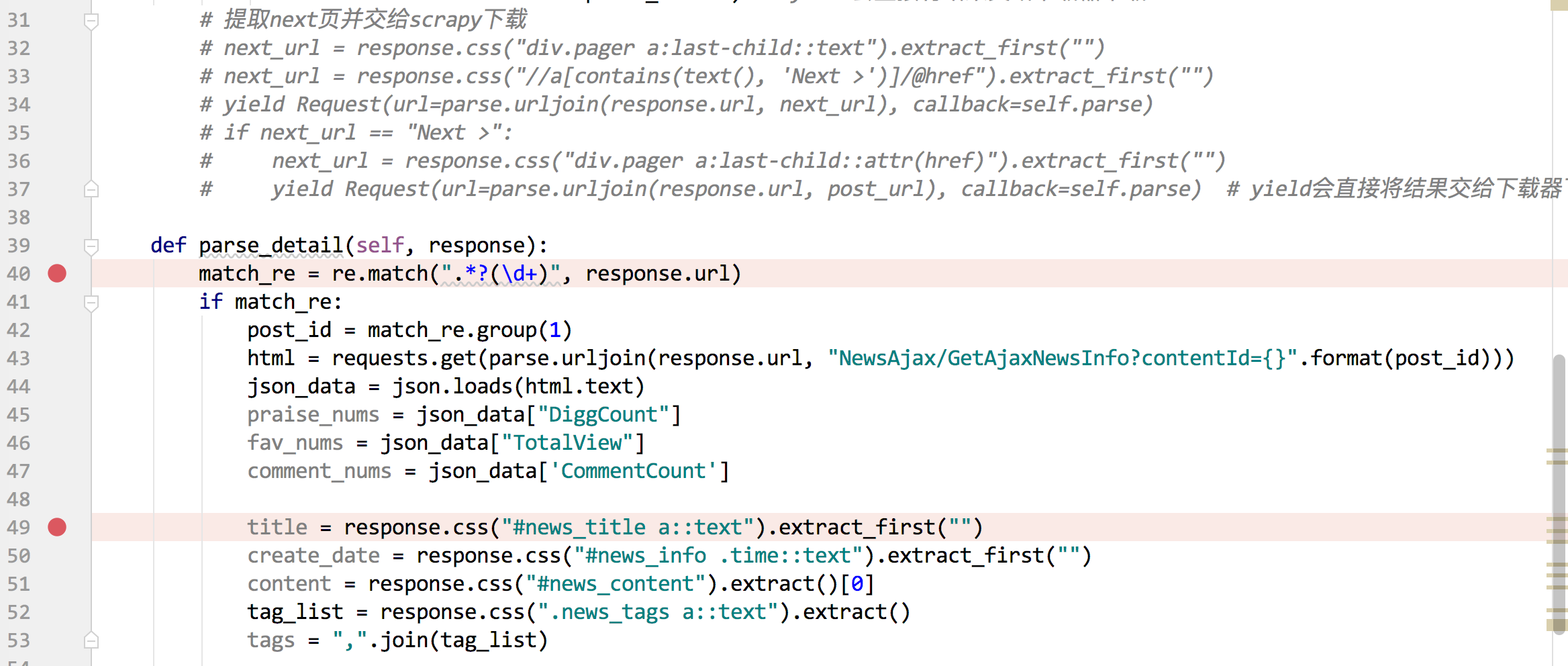
以下是Debug信息:
/Users/joker1937/opt/anaconda3/python.app/Contents/MacOS/python /Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevd.py --multiproc --qt-support=auto --client 127.0.0.1 --port 51860 --file /Users/joker1937/PycharmProjects/ArticleSpider/main.py
pydev debugger: process 5904 is connecting
Connected to pydev debugger (build 193.6494.30)
2020-05-05 23:01:49 [scrapy.utils.log] INFO: Scrapy 2.1.0 started (bot: ArticleSpider)
2020-05-05 23:01:49 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.9, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Python 3.7.6 (default, Jan 8 2020, 13:42:34) - [Clang 4.0.1 (tags/RELEASE_401/final)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Darwin-19.3.0-x86_64-i386-64bit
2020-05-05 23:01:49 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-05-05 23:01:49 [scrapy.crawler] INFO: Overridden settings:
{‘BOT_NAME’: ‘ArticleSpider’,
‘NEWSPIDER_MODULE’: ‘ArticleSpider.spiders’,
‘ROBOTSTXT_OBEY’: True,
‘SPIDER_MODULES’: [‘ArticleSpider.spiders’]}
2020-05-05 23:01:49 [scrapy.extensions.telnet] INFO: Telnet Password: 42ac7d43ee89d3bd
2020-05-05 23:01:49 [scrapy.middleware] INFO: Enabled extensions:
[‘scrapy.extensions.corestats.CoreStats’,
‘scrapy.extensions.telnet.TelnetConsole’,
‘scrapy.extensions.memusage.MemoryUsage’,
‘scrapy.extensions.logstats.LogStats’]
2020-05-05 23:01:49 [scrapy.middleware] INFO: Enabled downloader middlewares:
[‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware’,
‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware’,
‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware’,
‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware’,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware’,
‘scrapy.downloadermiddlewares.retry.RetryMiddleware’,
‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware’,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’,
‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware’,
‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware’,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’,
‘scrapy.downloadermiddlewares.stats.DownloaderStats’]
2020-05-05 23:01:49 [scrapy.middleware] INFO: Enabled spider middlewares:
[‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware’,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware’,
‘scrapy.spidermiddlewares.referer.RefererMiddleware’,
‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware’,
‘scrapy.spidermiddlewares.depth.DepthMiddleware’]
2020-05-05 23:01:49 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-05-05 23:01:49 [scrapy.core.engine] INFO: Spider opened
2020-05-05 23:01:49 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-05-05 23:01:49 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-05-05 23:01:49 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://news.cnblogs.com/robots.txt> from <GET http://news.cnblogs.com/robots.txt>
2020-05-05 23:01:50 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://news.cnblogs.com/robots.txt> (referer: None)
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 8 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 9 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 10 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 11 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 12 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 13 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 18 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 22 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 31 without any user agent to enforce it on.
2020-05-05 23:01:50 [protego] DEBUG: Rule at line 34 without any user agent to enforce it on.
2020-05-05 23:01:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://news.cnblogs.com/> from <GET http://news.cnblogs.com/>
2020-05-05 23:01:50 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://news.cnblogs.com/> (referer: None)
2020-05-05 23:01:50 [scrapy.core.scraper] ERROR: Spider error processing <GET https://news.cnblogs.com/> (referer: None)
Traceback (most recent call last):
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/utils/defer.py”, line 117, in iter_errback
yield next(it)
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/utils/python.py”, line 345, in next
return next(self.data)
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/utils/python.py”, line 345, in next
return next(self.data)
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py”, line 64, in _evaluate_iterable
for r in iterable:
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/offsite.py”, line 29, in process_spider_output
for x in result:
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py”, line 64, in _evaluate_iterable
for r in iterable:
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/referer.py”, line 338, in
return (_set_referer® for r in result or ())
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py”, line 64, in _evaluate_iterable
for r in iterable:
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/urllength.py”, line 37, in
return (r for r in result or () if _filter®)
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py”, line 64, in _evaluate_iterable
for r in iterable:
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/spidermiddlewares/depth.py”, line 58, in
return (r for r in result or () if _filter®)
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/core/spidermw.py”, line 64, in _evaluate_iterable
for r in iterable:
File “/Users/joker1937/PycharmProjects/ArticleSpider/ArticleSpider/spiders/cnblogs.py”, line 30, in parse
callback=self.parse_detail) # yield会直接将结果交给下载器下载
File “/Users/joker1937/opt/anaconda3/lib/python3.7/site-packages/scrapy/http/request/init.py”, line 42, in init
self._meta = dict(meta) if meta else None
ValueError: dictionary update sequence element #0 has length 0; 2 is required
2020-05-05 23:01:50 [scrapy.core.engine] INFO: Closing spider (finished)
2020-05-05 23:01:50 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{‘downloader/request_bytes’: 884,
‘downloader/request_count’: 4,
‘downloader/request_method_count/GET’: 4,
‘downloader/response_bytes’: 17703,
‘downloader/response_count’: 4,
‘downloader/response_status_count/200’: 1,
‘downloader/response_status_count/301’: 2,
‘downloader/response_status_count/404’: 1,
‘elapsed_time_seconds’: 0.641713,
‘finish_reason’: ‘finished’,
‘finish_time’: datetime.datetime(2020, 5, 5, 15, 1, 50, 436812),
‘log_count/DEBUG’: 14,
‘log_count/ERROR’: 1,
‘log_count/INFO’: 10,
‘memusage/max’: 104968192,
‘memusage/startup’: 104968192,
‘response_received_count’: 2,
‘robotstxt/request_count’: 1,
‘robotstxt/response_count’: 1,
‘robotstxt/response_status_count/404’: 1,
‘scheduler/dequeued’: 2,
‘scheduler/dequeued/memory’: 2,
‘scheduler/enqueued’: 2,
‘scheduler/enqueued/memory’: 2,
‘spider_exceptions/ValueError’: 1,
‘start_time’: datetime.datetime(2020, 5, 5, 15, 1, 49, 795099)}
2020-05-05 23:01:50 [scrapy.core.engine] INFO: Spider closed (finished)
Process finished with exit code 0
追加: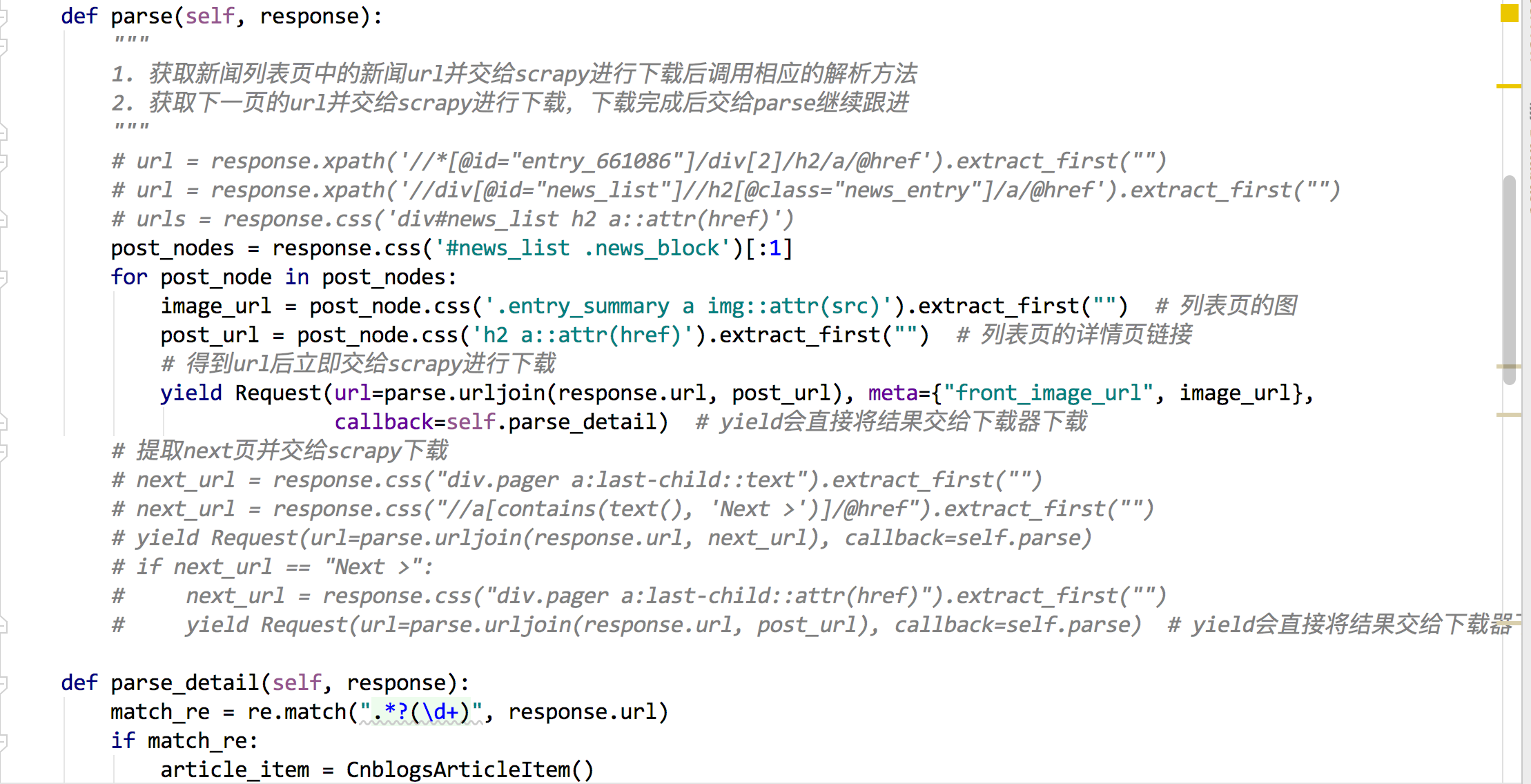
正在回答 回答被采纳积分+3
2回答

 字典用法都错了,字典是这样写的吗?
字典用法都错了,字典是这样写的吗? 这个地方的代码截图我看看
这个地方的代码截图我看看




- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











