获取初始页问题
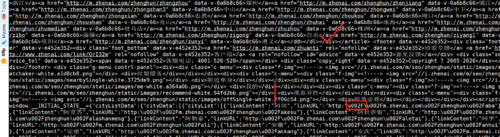
珍爱网http://m.zhenai.com/zhenghun 获取的源码有问题,http后面插入了unicode码,我用python倒是可以很方便的先过滤出unicode码然后decode为unicode-escape就解决问题了,Go语言不知道怎么实现,忘老师解惑。
941
收起
正在回答 回答被采纳积分+3
3回答


相似问题
数据获取问题
1116
0
7


请问有初始的课程源码吗?
693
0
5


关于首页轮播图片顺序问题
1847
0
6


老师 我觉得parse_topic()这段代码有点问题
916
0
5




类初始化时机的问题。
1309
0
2


登录后可查看更多问答,登录/注册


