样本数量与模型偏差和方差的关系
老师您好。通过8.5-8.7的学习,了解了模型的偏差、方差和模型复杂度的关系,认识到模型的复杂度(如degree的大小)是决定一个模型是欠拟合还是过拟合的重要因素。在“学习曲线”一节中,通过观察当模型的误差趋于稳定后,训练曲线与测试曲线的绝对大小和相对高低,来判断模型是过拟合还是欠拟合。由于还没涉及到集成学习的问题,这里每次训练都是用的训练数据集中的全部或绝大部分样本,因此第8章只关注了模型复杂度(如多项式拟合中的degree、knn算法中的n_neighbors以及后面决策树模型中的max_depth等参数)与方差或偏差的关系,没有关注每次抽取的样本量与方差或偏差的关系。
在后面有关bagging算法的学习时,了解到每个基模型(如BaggingClassifier中的一棵决策树)所选取的样本数量是一个超参数,可以人为设置,为了获取最优的超参数,就得研究每个基模型训练样本数量对偏差及方差的影响。当然可以使用网格搜索的方式选取最优超参数,但这样太费时且有时会受到随机因素的影响,因此想先从理论上分析一下每次抽取的样本数量(如BaggingClassifier中的max_samples参数)与模型泛化能力的关系。由于我数学基础不太好,所以尝试感性分析了一下,但在分析过程中陷入了死循环,所以还想请老师帮忙看一看:
1)若每次抽取的样本数较少,则样本很可能无法反映总体分布的规律,导致偏差高,同时,每个样本单次被抽中的概率小,即每次抽取时样本差异大,导致不同的基模型得到的拟合/分类模型差异较大,导致方差高;当增加每次抽取的样本数量时,样本反映总体分布的能力增强,偏差减小,并且每次抽取的样本重复率增大,不同基模型得到的拟合/分类模型差别变小,方差减小。这样看来,在n_estimators固定的前提下,单次抽取的样本数量越多,偏差、方差均越小,模型泛化能力越强?
2)但事实好像又不是这样,若每次选取的样本数增加,那么outlier被选中的概率增加,导致每个基模型受到outlier影响程度也会增加,这样反而是影响模型的泛化能力的。
我用make_moons数据做了以下实验(n=1000,noise=0.3,test_size=0.2,使用的是BaggingClassfier算法,单棵决策树的超参数使用默认参数),似乎证实了2)中的说法: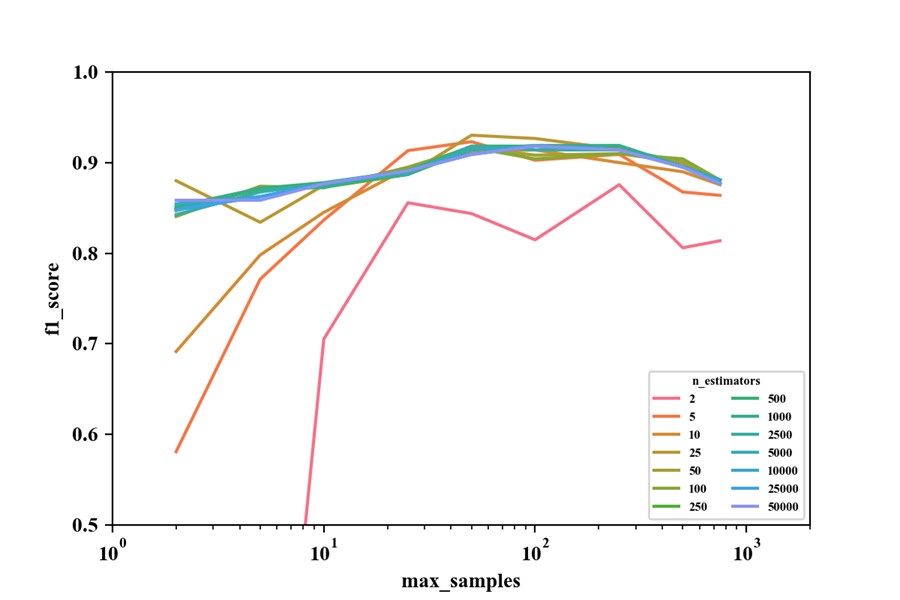
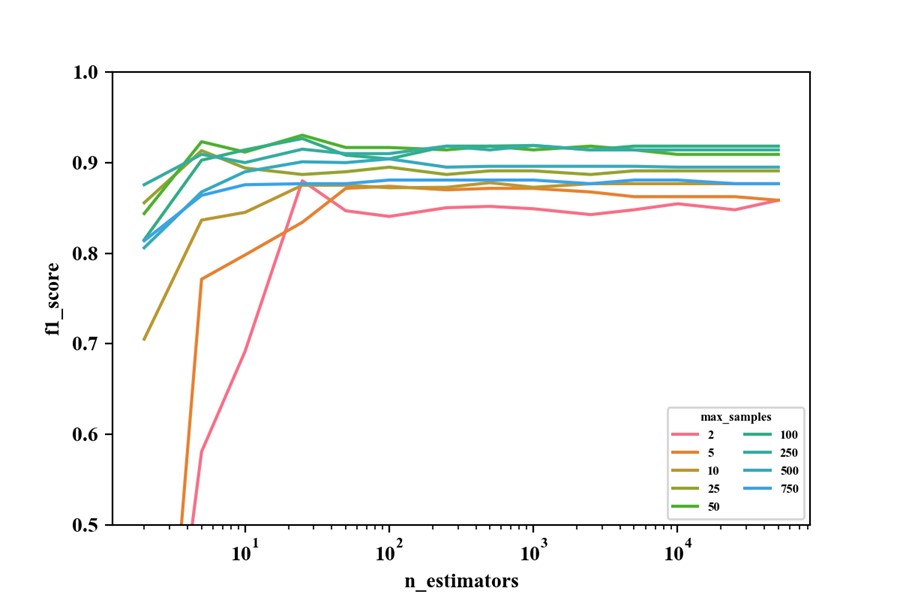
第一幅图中,n_estimators一定时,f1_score会随着max_samples的增加呈现出先上升后下降的趋势;第二幅图中,max_samples取较大值时,不管n_estimators取多少,其f1_score始终都不是最高的。
这样一来,max_samples不是越大越好实锤了吧?
但通过1)中的分析发现max_samples越大,方差、偏差均越小,泛化能力确实更好呀,这是矛盾了?
那么,是因为我在1)中的分析错了,还是除了方差和偏差之外,有第三个可以评价模型泛化能力的指标呢?
谢谢!:)
正在回答
1回答
相似问题



登录后可查看更多问答,登录/注册







