测试数据集PCA问题
老师您好。
请问X_train数据集进行PCA之后,X_test数据集也需要进行PCA吗?
当我使用网格搜索,在Pinepline内进行逻辑回归后(内含PCA),直接对测试数据集进行grid_search.best_estimator_.score(X_test,y_test)操作,得到的准确率和我对X_test进行PCA后的准确率不一样。
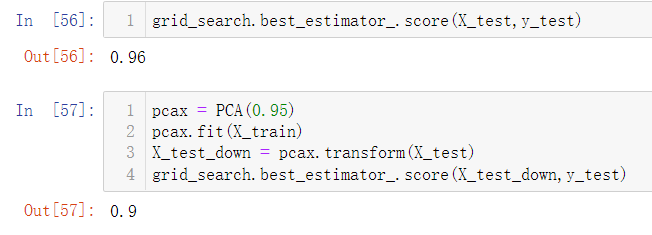
我理解中X_train数据集在PCA之后坐标轴就发生了改变,那么按道理测试数据集也应该进行PCA?但是不是说测试数据集不能改动吗?
有点疑惑,下面贴上代码。
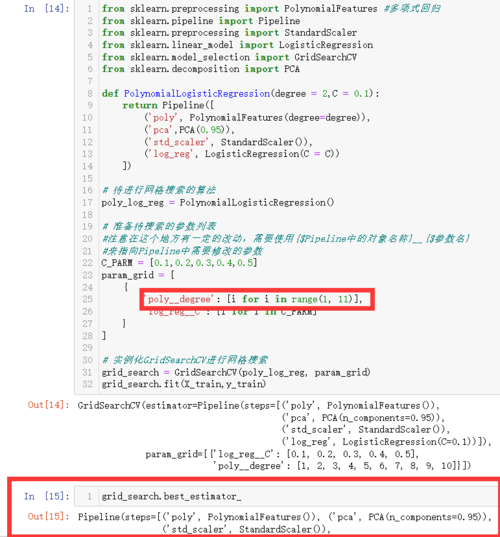
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
def PolynomialLogisticRegression(degree = 2,C = 0.1):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('pca',PCA(0.95)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C = C))
])
# 待进行网格搜索的算法
poly_log_reg = PolynomialLogisticRegression()
# 准备待搜索的参数列表
#注意在这个地方有一定的改动,需要使用{$Pipeline中的对象名称}__{$参数名}
#来指向Pipeline中需要修改的参数
C_PARM = [0.1,0.2,0.3,0.4,0.5]
param_grid = [
{
'poly__degree': [i for i in range(1, 11)],
'log_reg__C': [i for i in C_PARM]
}
]
# 实例化GridSearchCV进行网格搜索
grid_search = GridSearchCV(poly_log_reg, param_grid)
grid_search.fit(X_train,y_train)
grid_search.best_estimator_.score(X_test,y_test)
>>>输出:0.96
pcax = PCA(0.95)
pcax.fit(X_train)
X_test_down = pcax.transform(X_test)
grid_search.best_estimator_.score(X_test_down,y_test)
>>>输出:0.9
1146
收起
正在回答
2回答

相似问题

请问老师,关于识别MNIST手写数据集的问题
1501
0
4


感觉如果验证数据叫测试数据,测试数据叫验证数据是不是更好些?
1572
1
2
PCA中样本均值归零与前N个主成分问题
1729
0
6
用来预测的数据怎么做数据预处理呢
1442
0
4
登录后可查看更多问答,登录/注册








