老师,运行京东网的爬虫出现错误
我在运行京东网爬虫爬取其他书的信息时,有时会出现下面的错误: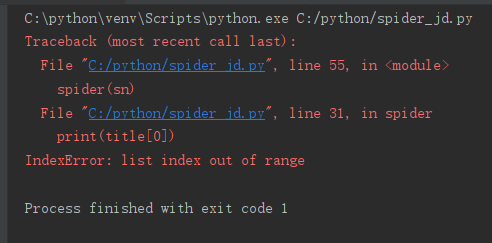
上网查询后,发现是京东网在title列表中的值是空,因为爬不到东西,所以越界了。
后来我修改了代码,做了一个逻辑运算,当title[0]为空时输出‘无’,有东西时就直接输出,代码如下: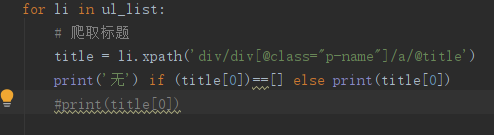
可是,结果还是报错: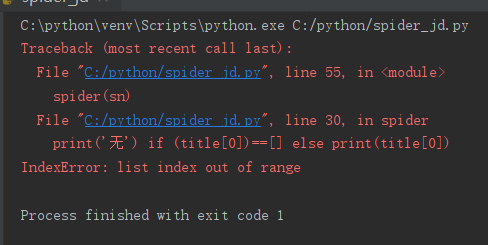
请问老师,我的想法是对的吗?错在哪里了?
老师,我后面发现是京东网的网页源代码有两种,所以有时爬虫运行正常有时又报错: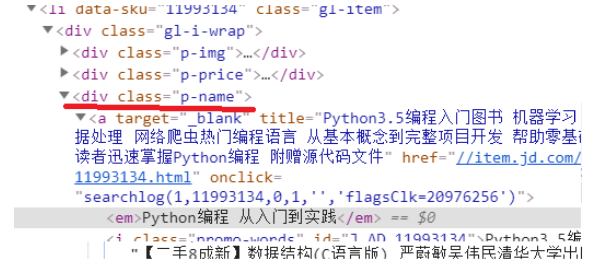
这里class后面的是“p-name”
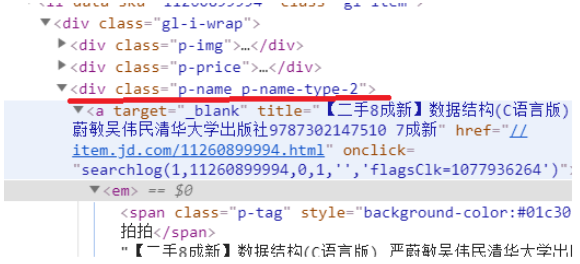
这里class后面又变成了“p-name p-name-type-2”了
怎样做出一个逻辑判断,让在爬取第一个@class="p-name"取不到内容时,自动去爬取@class="p-name p-name-type-2"里面
的内容呢?还是if else判断吗?
1504
收起
正在回答
1回答

相似问题



登录后可查看更多问答,登录/注册






