scrapy-redis中master和slave的通信
老师,从这节课看scrapy-redis的入口是name:start_urls,那slave端要如何获取master端存入name:requests的请求呢,从master那yield的话应该也没办法回调slave上的处理函数吧,是有提供方法还是需要我自己重写相关的源码
970
收起
正在回答
1回答

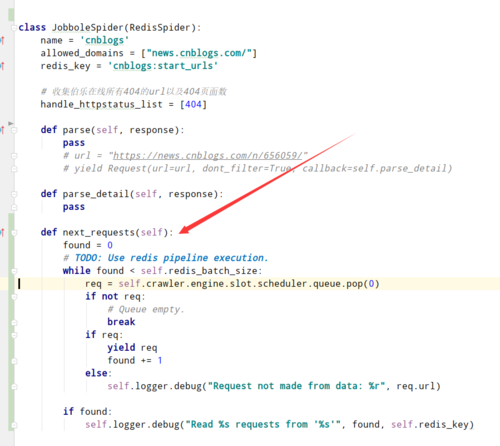 如果是slave 那么重写这个方法就行了, 记住 master不要这么写, 我把这个代码给你贴一下:
如果是slave 那么重写这个方法就行了, 记住 master不要这么写, 我把这个代码给你贴一下:

Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











