逻辑回归算法提示算法不收敛
样本特征为5个,标签有6种,使用多项式逻辑回归,多项式次数degree设置为5,L2正则化,OvO多分类,运行的时候警告线性算法没有收敛,而且分类准确度很低(百分之45左右,kNN可以达到80),。是数据太复杂了维度太多了吗?degree设置为10后,直接超出10000的迭代次数限制了。
老师我想问一下,在网格搜索合适的degree、C的时候,搜索范围设置在多少比较合适?造成算法预测准确度这么低的原因会有哪些?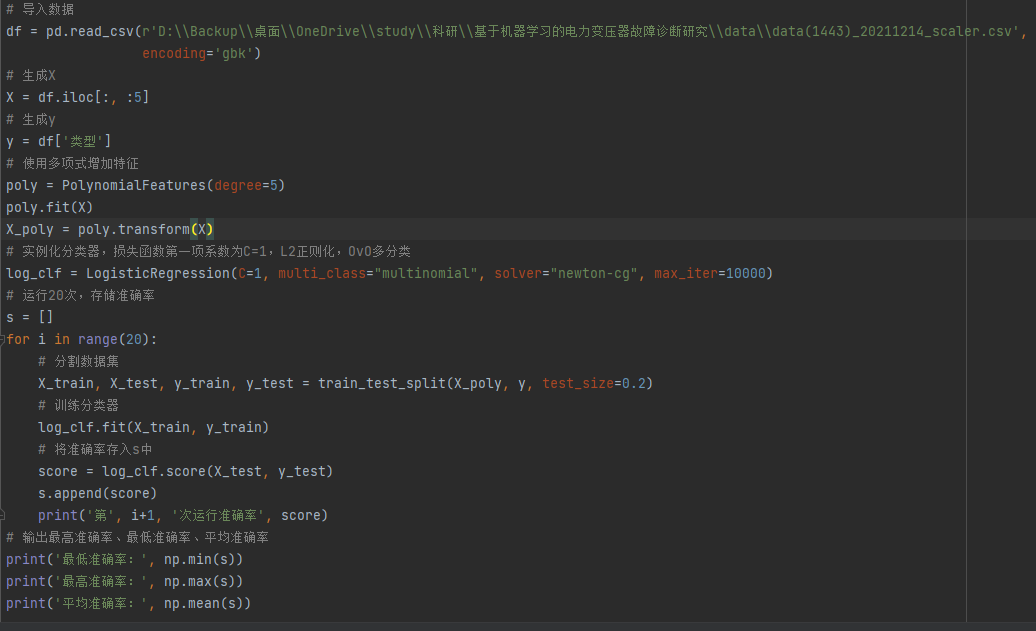

2308
收起
正在回答 回答被采纳积分+3
1回答
相似问题
逻辑回归算法小问题
996
0
1


mnist 逻辑回归不收敛
2203
0
8


想问一个之前面过的算法题
756
0
3


关于递归算法的提问?
1204
0
3
问下逻辑回归中的“逻辑”是什么意思,为什么叫逻辑,是怎么来的?
3430
1
4
登录后可查看更多问答,登录/注册








