Dataset.interleave()的理解是否正确
*****tf.data.TextLineDataset(filename)*****是读取文件生成一个dataset,那么读了这么多文件,最后却是一个dataset,是因为Dataset.interleave()把dataset合并成一个更大的了吗?老师说的read file -> dataset -> datasets -> merge 就是指这个过程吗?
参数cycle_length是并行读取的数量,也就是同时读取五个文件,每个文件读一行,所以会出现输出结果开始先读了每个文件的header。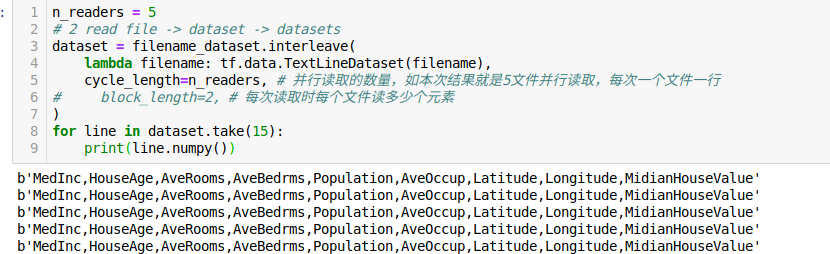
参数block_length是每次读文件读几行,所以如果我把这个参数设为2,就会在并行读取时每次读2个了: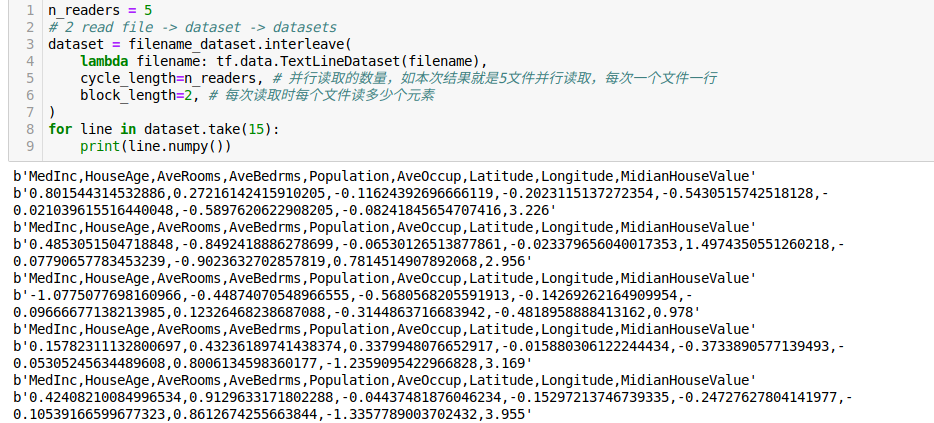
这样的理解是否正确呢?
1403
收起
正在回答 回答被采纳积分+3
1回答

相似问题
对于这节课的代码理解,老师看下是否正确
853
0
1


nginx正向代理
1421
0
4




对系统软件的理解不知是否正确
1111
1
2


正向代理问题
1289
0
6


请问老师我的理解正确吗
620
0
1


登录后可查看更多问答,登录/注册




