集成selenium后的爬虫无法通过api关闭是什么原因?
我集成了selenuum的爬虫都无法通过api关闭,不知道是怎么回事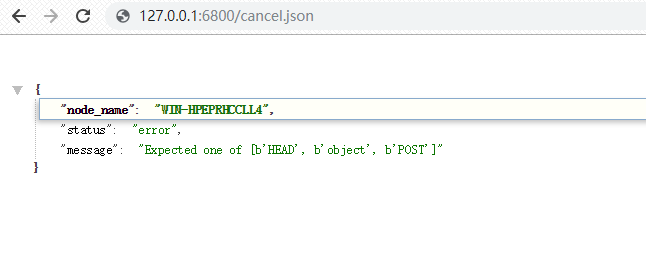

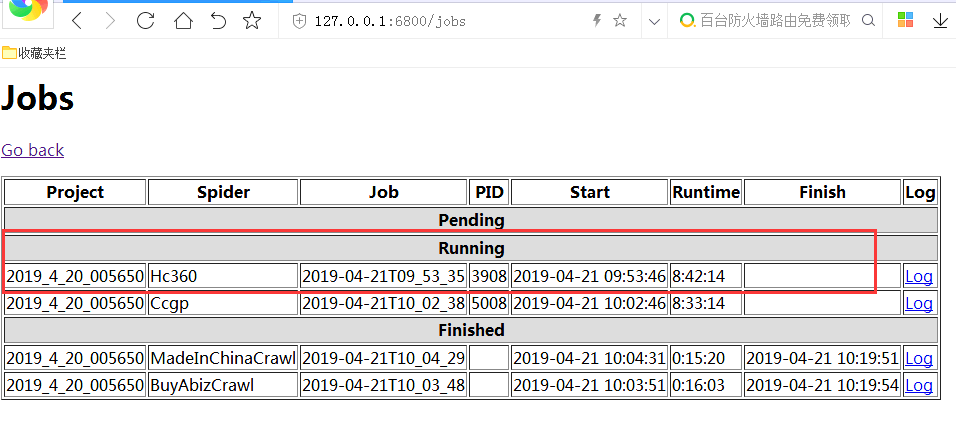
所有的爬虫中,只有集成了selenium的无法关闭,其他没有集成的都能正常关闭
我的代码:
【爬虫】
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
from selenium import webdriver
from items import BuyinfoItem, SellinfoItem, CompanyinfoItem
from utils.common import suiji_str, html_geshi, zhsha256, img_random, date_Handle, address_Handle,qq_Handle,url_qian
from utils.xpath_rule import RuleInfo
class CcgpSpider(RedisCrawlSpider):
name = 'Ccgp'
wait = 1
allowed_domains = ['www.ccgp.gov.cn']
redis_key = '{0}:start_urls'.format(name)
xp = RuleInfo().obtain(name)
rules = (
Rule(LinkExtractor(allow=(xp['Rule.buy.html'],xp['Rule.buy.html2'])),
callback='buy_html', follow=True),
Rule(LinkExtractor(allow=(xp['Rule.parse.list'], xp['Rule.parse.list2'])), callback='parse_list', follow=True),
)
def __init__(self, **kwargs):
# 加载动态页面
chrome_opt = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_opt.add_experimental_option("prefs", prefs)
self.browser = webdriver.Chrome(chrome_options=chrome_opt)
super(CcgpSpider, self).__init__(**kwargs)
dispatcher.connect(self.spider_closed, signals.spider_closed)
def spider_closed(self, spider):
# 关闭蜘蛛浏览器
self.browser.quit()
def parse_list(self, response):
# 中央单位采购公告
urllist = response.xpath(self.xp['parse.list.urllist']).extract()
pageurl = response.urljoin(response.xpath(self.xp['parse.list.pageurl']).extract_first(""))
if urllist:
for url in urllist:
url = response.urljoin(url)
yield scrapy.Request(url,callback=self.buy_html)
if pageurl:
yield scrapy.Request(pageurl,callback=self.parse_list)
def buy_html(self, response):
# 采购招标详情页
es_id = suiji_str()
title = response.xpath(self.xp['buy.html.title']).extract_first("")
tags = response.xpath(self.xp['buy.html.tags']).extract_first("").replace("/", ",")
content = ""
htmltext = html_geshi(response.xpath(self.xp['buy.html.htmltext']).extract_first(""))
content = content + htmltext
url = response.url
url_id = zhsha256(url)
img_url = ""
company = response.xpath(self.xp['buy.html.company']).extract_first("")
fabu_date = date_Handle(response.xpath(self.xp['buy.html.fabu_date']).extract_first(""))
# 传递Item
BuyInfo = BuyinfoItem()
BuyInfo['es_id'] = es_id
BuyInfo['title'] = title
BuyInfo['tags'] = tags
BuyInfo['content'] = content
BuyInfo['url'] = url
BuyInfo['url_id'] = url_id
BuyInfo['img_url'] = img_url
BuyInfo['company'] = company
BuyInfo['fabu_date'] = fabu_date
yield BuyInfo
【middlewares】
class JsPageMiddleware(object):
"""通过Chrome访问动态网页的请求设置"""
def __init__(self, crawler):
self.reurl_list = crawler.settings.get("CHROME_NAME", "")
# 加载动态页面
super(JsPageMiddleware, self).__init__()
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
# 根据URL判断是否启动Chrome
for names in self.reurl_list:
if spider.name == names:
spider.browser.get(request.url)
w = spider.wait
time.sleep(w)
print("访问:{0}".format(request.url))
if re.search(r"latestBuy\.html$",request.url):
# 慧聪网最新采购页
spider.browser.find_element_by_xpath("//*[@id='qg-T1']").click()
time.sleep(w)
spider.browser.find_element_by_xpath("//*[@id='qg-T2']").click()
time.sleep(w)
elif re.search(r"list/caigou\.shtml$",request.url):
spider.browser.find_element_by_xpath("//div[@class='quoteList']/p/a").click()
time.sleep(w)
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)
1116
收起
正在回答 回答被采纳积分+3
2回答

相似问题
部署爬虫中cancel不起作用
1051
0
2




scrapyd部署scrapy后无法关闭爬虫
1990
0
1
关于爬虫发展前景
1846
0
4
如何避过验证码post过多限制的反爬
1283
1
2


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











