学习爬微博网站遇到的问题,请求解答,谢谢
爬取微博网站 个人信息,关注数、粉丝数和微博,三个指标;
css语句:response.css(".WB_main_r .user_atten li::text").extract(), 返回的结果一直是空列表 [ ]。
下面是网页截图
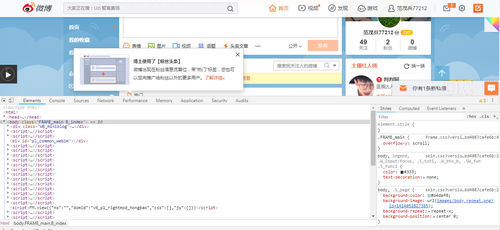
下图是右键查看源码的代码,与上图中代码不一样。这样的情况下,是以源码为准来css定位爬取吗?

这里的代码基本都在</script>标签内。例如代码结构下
<script>FM.view({"pid":"plc_frame","js":["home\/js\/pl\/lib.js?version=b1d20fbbbb3d0864"],"jsDefer":true});</script><div id="pl_common_webim"></div>
对于<script>FM.view()这样的代码如何css定位爬取?
另外,能够帮忙给出爬取 关注数、粉丝数和微博三个指标的css语句,十分谢谢!!!
1198
收起
正在回答
2回答

相似问题





登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











