session.get()会话能否加上代理ip和随机ua
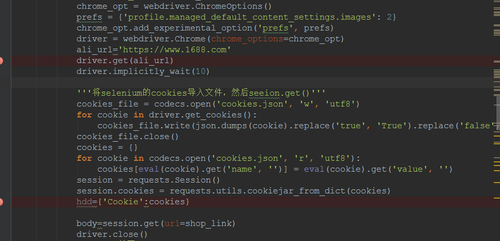
请问老师:session.get()能否加上代理ip和随机ua请求,session里面是带上selenium的cookies,速度快很多。但是抓不到100条数据就被识别到,只要用selenium启动chrome就被识别。我用本地浏览器访问是没问题。所以我就怀疑阿里巴巴是根据selenium启动chrome的ua和ip地址来封我的。,这种情况如何破解?
1657
收起
正在回答 回答被采纳积分+3
1回答

相似问题






登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











