selenium 集成到scripy后,点击翻页问题
我parse里能正常采集值存了,原本的在parse里判断是否有下一页标签,再交个Request,callback=parse.,现在需要selenium来点击下一页按钮,怎么做呢?
我这样没成功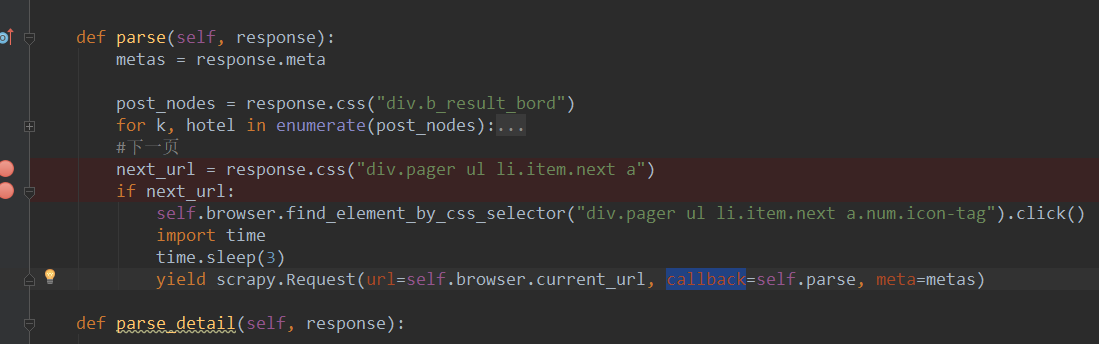
在browser.click()这就报错停了
2172
收起
正在回答 回答被采纳积分+3
4回答

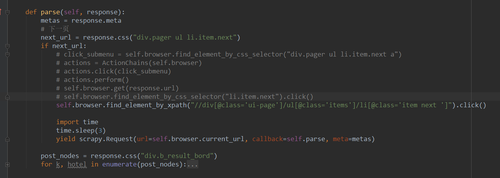
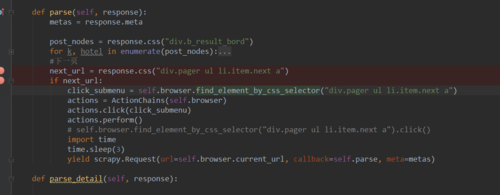
相似问题
老师,有些网站下一页的url是js生成的 selenium直接点击报错
1243
0
3



上翻页时会出错
936
0
2




selenium 模拟点击成空白问题
2195
0
2
scrapy+selenium滚动翻页
941
0
3
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











