页面内list图片下载问题
尝试着爬一些食谱类网站,
食谱:
-标题
-步骤
–步骤编号
–步骤图片
–步骤描述
-食材
–食材名
–食材用量
…
采集信息会以json形式存进firebase或者mongodb.
每个食谱下都会有好几个步骤描述和图片。
直接下载图片的话,会产生图片和步骤错位(有些步骤可能没有图片)
目前的做法就是把步骤通过ItemLoader来提取解析,然后分解成步骤文字,步骤图片,步骤编号, 但是这样图片文件又不能进入ImagePipeline 进行下载
想过把步骤作为一个新的item,发送请求Request,然后回调。但是这样做会产生大量无用请求(同一页面,如有十个步骤,感觉就要发送十次请求和回调。试过用meta来把步骤传给下一个parser但是 meta传的数据和response不是一个数据类型 没法加入itemloader。) (scrapy 应该会过滤掉同一页面的请求。。。所以这个方法也不行)
想请问有没有其他比较好的方法解决这个食谱步骤极其图片的采集和存储问题。
至于ImagePipeline图片字段问题,通过官方文档介绍,外加新的ImagePipeline和对应IMAGES_URLS_FIELD。这块问题不大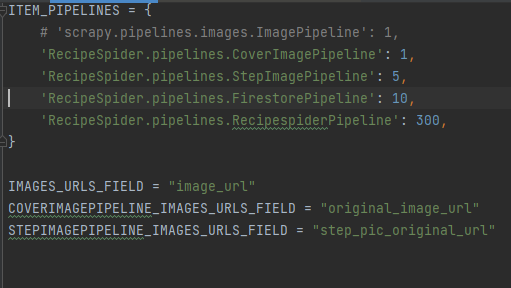
745
收起
正在回答 回答被采纳积分+3
1回答
相似问题
关于图片加载完的问题
1573
0
5


404图片
1569
0
6




不能自动刷新list页
1142
0
6


关于首屏加载优化之图片懒加载
1077
0
7


为什么withloader 图片跟随着图标一直加载
1089
1
4


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











