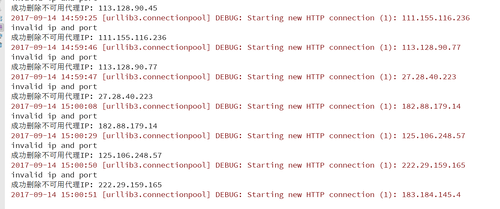
请求百度验证IP是否可用,一直有exception 截屏
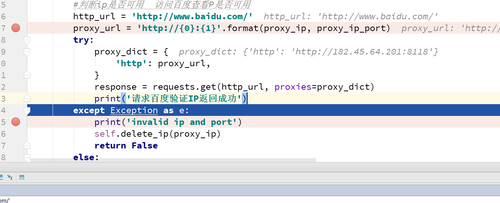
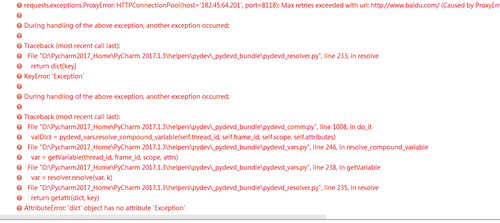
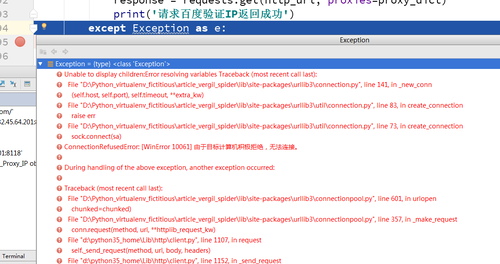
debug 运行了几次都是 invalid ip and port 感觉代码没有问题,好像请求百度是不是失败了?
1010
收起
正在回答 回答被采纳积分+3
5回答


相似问题
新浪微博模拟登录,验证码问题
1836
0
3


淘宝请求百度,cookie问题
1335
0
3




可以获取微信的GET请求 ,但验证失败
1994
0
14




验证码
1087
0
9
老师,验证码那还是有问题
1214
0
5


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











