使用Crawlera后,response.body为空,取不到信息
老师您好。我按照课程内容完成了User-Agent设置和Crawlera的IP设置,去爬取大众点评网的信息,现在遇到一个问题。在我启用Crawlera之后,response.body基本上都是空的,提不出任何信息。反倒是我没启用Crawlera的话,大部分情况下response.body是正常的,可以取到信息,但是有一定几率会碰到403。请问这是什么原因呢?该如何解决?
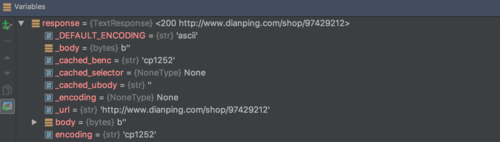
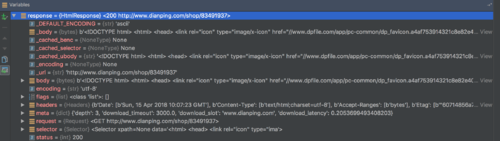
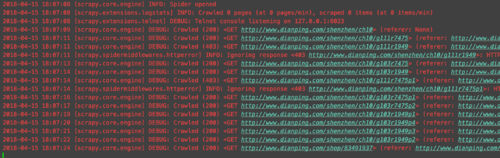
PS:我已经尝试了设置DOWNLOAD_TIMEOUT为3000,以及设置DOWNLOAD_DELAY为1,均未能解决问题。
1120
收起
正在回答 回答被采纳积分+3
1回答

相似问题









登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











