UnicodeEncodeError: 'gbk' codec can't encode character '\u200b'
import requests
def zhihu_test():
url = "https://www.zhihu.com/question/320649155/answer/899683765"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36",
}
response = requests.get(url=url, headers=headers)
return response
res1 = zhihu_test()
print(res1.text)
"""
错误代码
C:\Users\Administrator\Envs\scrapy_env\Scripts\python.exe D:/ArticleSpider/ArticleSpider/utils/zhihu_requests.py
Traceback (most recent call last):
File "D:/ArticleSpider/ArticleSpider/utils/zhihu_requests.py", line 16, in <module>
print(res1.text)
UnicodeEncodeError: 'gbk' codec can't encode character '\u200b' in position 6699: illegal multibyte sequence
"""
"""
把注释去掉 我的解决方法替换里面\u200b 为空,可以打印出来
"""
# res2 = res1.text.replace(u'\u200b', u'')
# res3 = res2.replace(u'\xba', u'')
#
# print(res3)
"""
请问次方法可行吗?会有什么问题?
还有重要问题没有解决,每个网页返回错误gbk后面 character数据都不一样,如何解决,昨天熬一晚
最后数值都不一样,会造成打印不出来和写入html文件错误
"""
833
收起
正在回答 回答被采纳积分+3
1回答

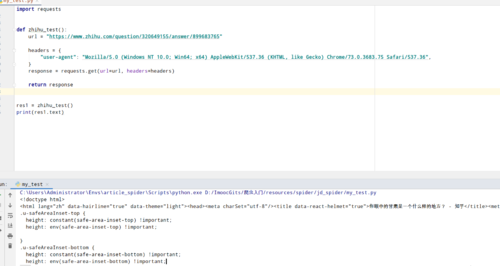 这是我这里的运行情况,你这里报错是当前的代码引起的吗?
这是我这里的运行情况,你这里报错是当前的代码引起的吗?


Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











