cnblogs模拟登录出错错误
# -*- coding: utf-8 -*-
import multiprocessing
import scrapy
from scrapy import Selector
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
custom_settings = {
"COOKIES_ENABLED": True
}
def start_requests(self):
# 入口可以模拟登入拿到cookie,selenium控制浏览器会被一些网站识别出来例如知乎,拉勾
import undetected_chromedriver.v2 as uc
browser = uc.Chrome()
browser.get("https://account.cnblogs.com/signin")
print("_______________")
# 自动化输入,自动化识别滑动验证码并拖动
input("回车继续:")
# 拿到cookie
cookies = browser.get_cookies()
cookie_dict = {}
for cookie in cookies:
cookie_dict[cookie['name']] = cookie['value']
for url in self.start_urls:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 将cookie交给scrapy, 后续的请求会请求之前的cooked吗?
yield scrapy.Request("https://news.cnblogs.com/n/709266/", cookies=cookie_dict, headers=headers,dont_filter=True)
def parse(self, response):
sel = Selector(text=response.text)
url1 = sel.css('#news_list h2 a::attr(href)').extract()
url = response.css('#news_list h2 a::attr(href)').extract()
pass
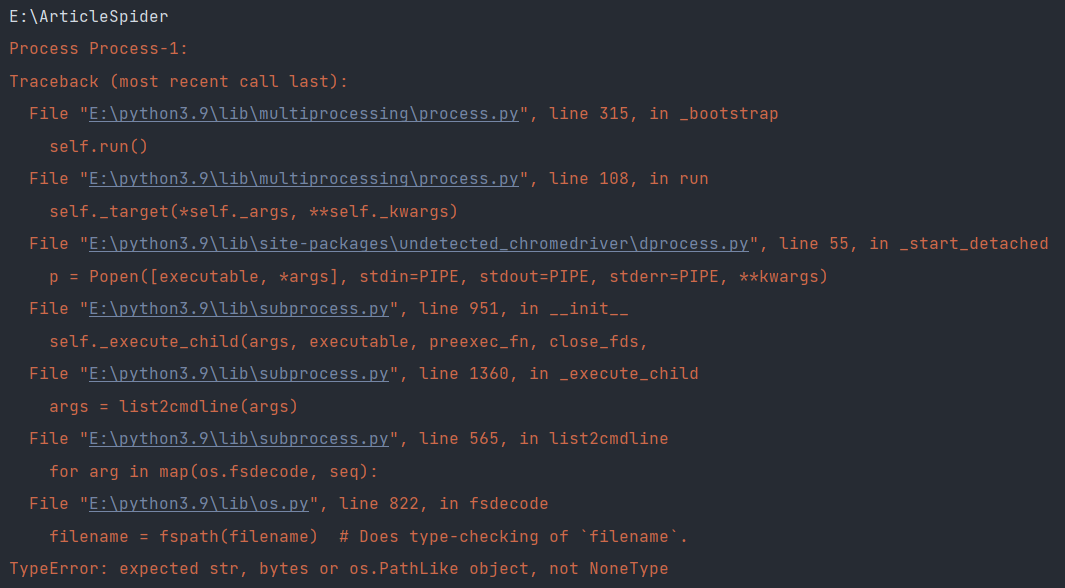
718
收起
正在回答 回答被采纳积分+3
1回答
相似问题
302错误
1413
0
3


爬虫cnblogs提示错误
881
0
7


老师像美图那个登录要手机验证码的怎么解决啊
1374
0
3


cnblogs scrapy shell response 443
1004
1
4


cnblogs刚刚抓取就出现302
970
0
2
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











