问下您这个boosting的网格搜索怎么出错了,是哪里写的不对呢
param_grid = [{‘base_estimator_alpha’:[0.01,0.1,1,10,100],‘n_estimators’:[200,300,500]}]
from sklearn.linear_model import Ridge
ada_reg = AdaBoostRegression()
grid_search = GridSearchCV(AdaBoostRegression(Ridge(alpha=100),n_estimators=100),param_grid)
grid_search.fit(x_poly,y)
print(grid_search.best_params_)
print(‘grid_search.best_score_:%4f’%grid_search.best_score_)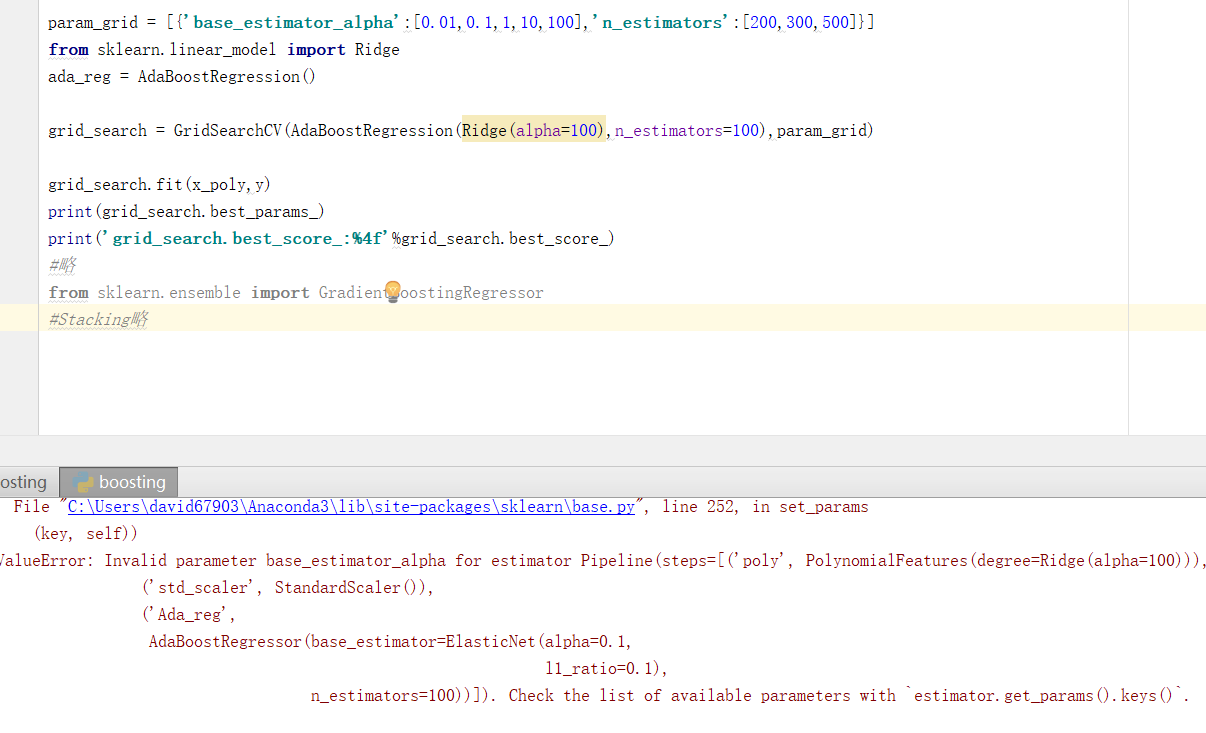
763
收起
正在回答 回答被采纳积分+3
1回答

相似问题






登录后可查看更多问答,登录/注册








