难例挖掘没听明白
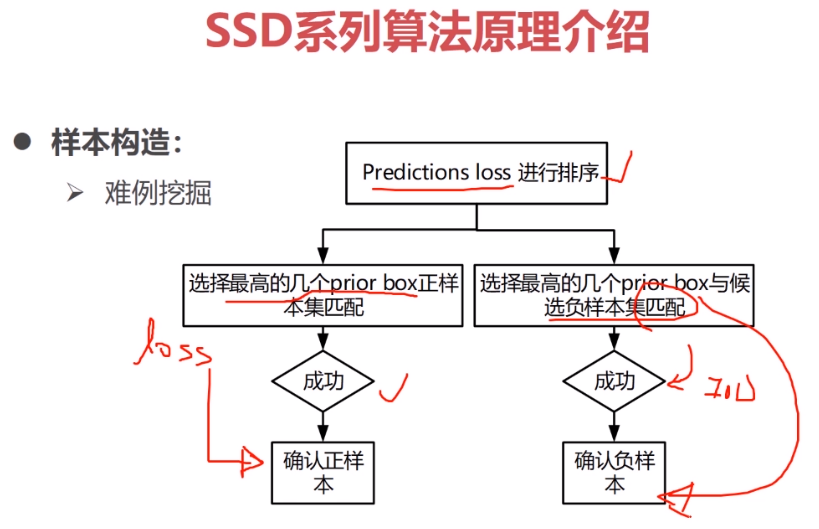
Prediction、Loss是怎么计算的?
我的理解是prediction loss高的就是用这个prior box,预测里面有目标的分类效果不好,loss就会高。(其实里面根本没有目标物体?)
然后这些loss高的priorbox要分别与正样本集和负样本集 算IOU?再加入正负样本集?既然是loss高的prior box加入到原来的正负样本集 是否会污染样本集?
难例应该就是预测效果不好的那些prior box吧?就是prediction loss高的那些,如果是这样,第一步其实对他们进行降序排序的时候就得到了topN的难例了。后续的操作没明白是在做什么。。。
1139
收起
正在回答 回答被采纳积分+3
1回答

相似问题
学完了这门课,是否有资格做数据挖掘的相关工作了呢?
1408
0
6


大数据里面加上数据挖掘算法
803
0
2


工业领域数据挖掘
1242
2
6

比特币中算的哈希值需要跟目标值比较。那么目标值是谁给定的呢?
1613
0
3


登录后可查看更多问答,登录/注册






