爬虫的网页格式
直接从网页复制下来的html代码 和 python经 str转码后爬下来的不一样,好像少了很多
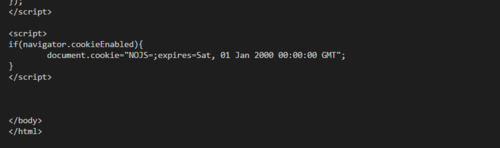
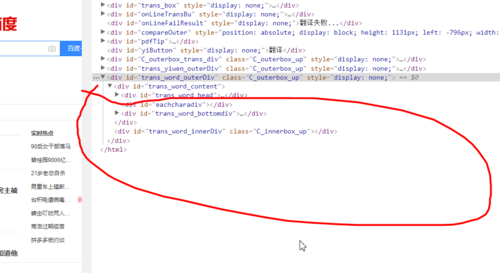
上面两张都是代码末尾的部分,但python爬下来的和F12直接看到为什么不一样。
1300
收起
正在回答 回答被采纳积分+3
1回答
相似问题
爬虫
1328
2
8




请问源代码有实现scrapy-redis对招聘网站进行分布式爬虫吗
1132
0
5


老师下一门的Python爬虫系列实战课程是《高级爬虫工程师》?
1159
0
3
老师,运行京东网的爬虫出现错误
1494
1
6


登录后可查看更多问答,登录/注册















