参数设置
从上到下依次为图1,图2[滑到最底端]
1.为什么max_length设置成500,依据什么设置的?
2.7-2中的vocab_size=10000依据是什么
3.每个词对应的数字映都要映射成16长度的向量么,如下图1所示
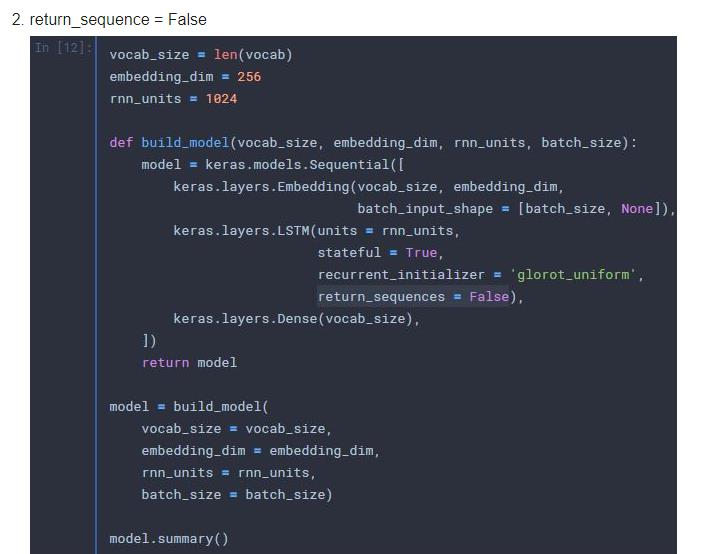
4.为什么7-5同学提的问题中的vocab_size写的是len(vocab),
但是老师在7-3中却将vocab_size设成了一个常量10000,而不是vocab的长度?
如下图2所示:
541
收起
正在回答
1回答

相似问题
品类表关联设置参数表问题
1166
1
3


参数化的数据如何设置文本检查点?
971
0
5




login.do测试,500 空指针异常,参数没传过来??
1728
0
2


I,B,P帧问题
956
0
3


参数设置
1205
2
3


登录后可查看更多问答,登录/注册




