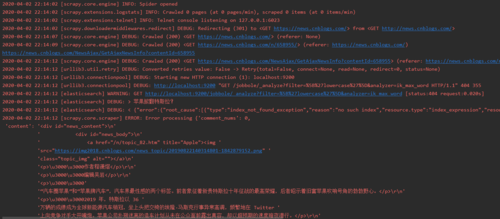
博客园就爬取一条就停止了,连接es出了问题

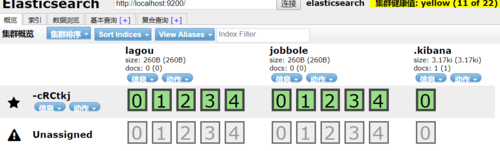
我可以通过es_types来创建索引
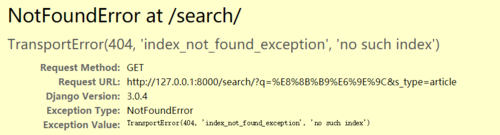
那看来是数据导入es那里有问题
我是直接运行您的代码的
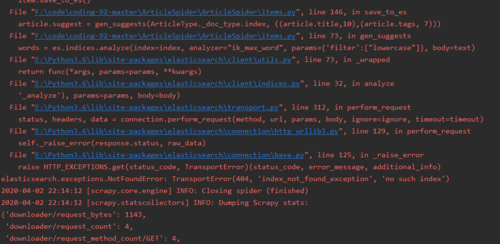
还有前端 TransportError(404, 'index_not_found_exception', 'no such index')
1571
收起
正在回答 回答被采纳积分+3
2回答



相似问题

登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











