决策树的应用场景
在使用决策树进行回归问题时,我发现X_test准确率并不高,后面我使用了交叉验证也得出同样的结论,准确率不高(平均0.7),在进行了归一化,网格搜索【‘max_depth’ ‘min_samples_split’‘min_samples_leaf’】找到最好的参数之后,准确率还是不高(0.77)。
所以我就绘制一下学习曲线
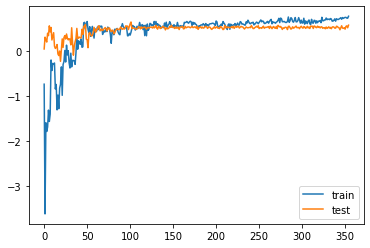
我得出以下几点结论
(这图片我省略了前20个准确率数据(train_score)因为波动很大)
(网格搜索时从5个数据开始的)
- 从前几个波动很大,可以看出来决策树对于数据的变动也很敏感。
- 决策树似乎不适合用于这个数据集合
- 提高数据总量m确实能缓慢增长准确率
- 在train曲线升高之后test曲线缓慢的下降,发生了过拟合,这一点不知道是不是因为决策树本身容易发生过拟合
我的问题是:我以后遇到什么情况,或者那种类型的数据,应该考虑使用决策树方法来解决,(我总觉得决策树横平竖直,算的又慢,有点笨)
1748
收起
正在回答
1回答

相似问题



登录后可查看更多问答,登录/注册








