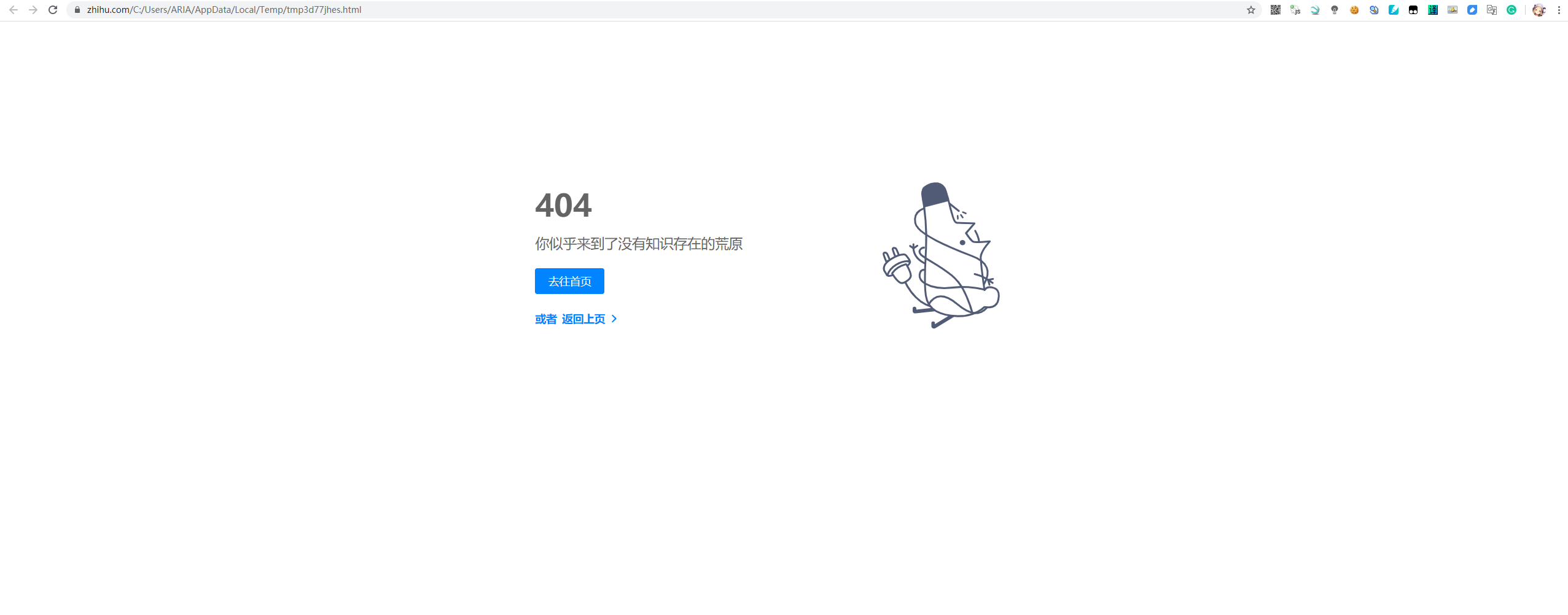
scrapy shell添加了useragent参数 返回状态码是200 但是页面显示404
scrapy shell在添加了useragent后 虽然返回的response状态码是200 但是view(response)打开返回的response发现返回的页面写着404
我使用的语句:
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36" https://www.zhihu.com/question/339753020
1672
收起
正在回答
2回答
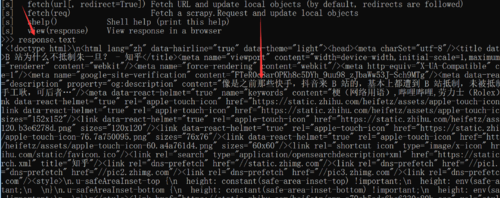 你要在cmd中运行,不要保存到html中然后去查看html文件
你要在cmd中运行,不要保存到html中然后去查看html文件相似问题
4-8,返回的404是干嘛的?
784
0
2


10-11 章 注册返回200 还是注册失败
1675
0
7




在终端中 scrapy shell 如何避开302重定向呢?
1311
0
4


商品分页
1231
1
5


非'000000'情况下返回200状态码
944
1
5




登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











