关于filtered duplicate request的疑惑?
老师,下面日志中这个filtered duplicate request让我很疑惑: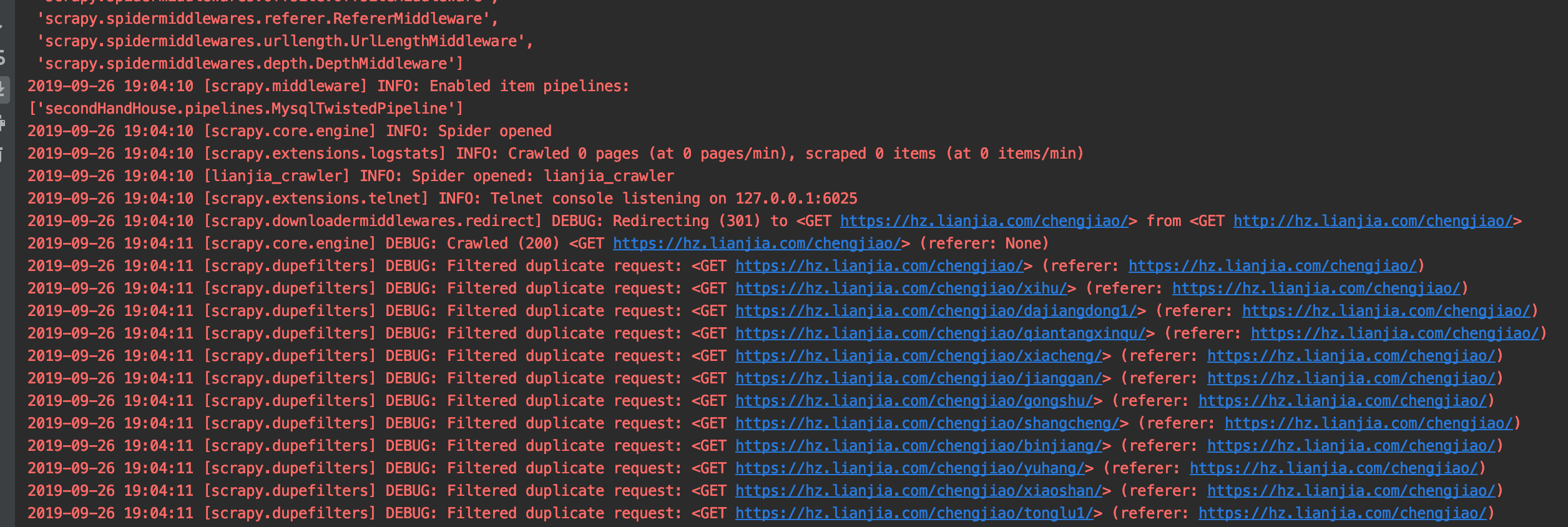
这些request看上去像是在 dont_filter=False 的情况下被过滤掉的,但是我的spider脚本如下: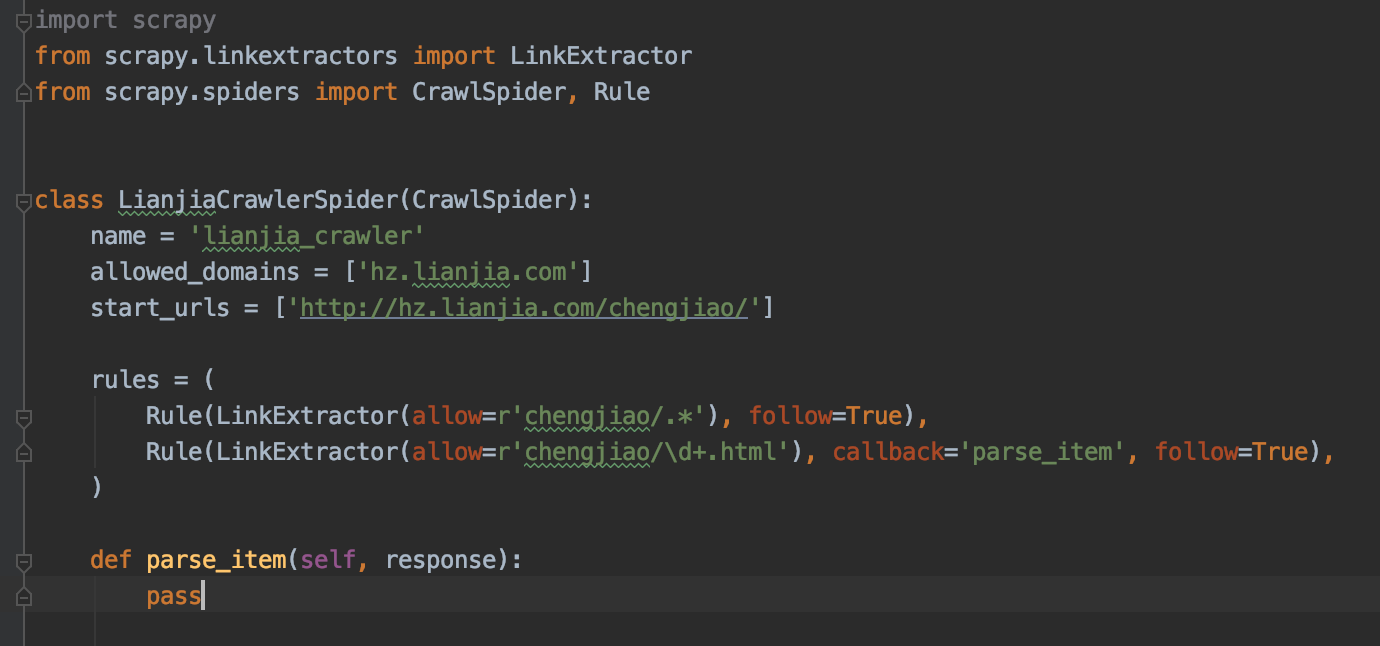
这些被过滤掉的URL, 例如 hz.lianjia.com/chengjiao/xihu/ 明明是第一次取,却被filtered,看上去很像是由于和 hz.lianjia.com/chengjiao/ 重了而被去重的.
但是这两个URL明显是不一样的.不符合scrapy的去重规则呀, 请问老师这个URL被filtered的原因是什么?
1457
收起
正在回答
3回答

相似问题
filtered offsite request的疑惑?
762
0
1


关于cas的疑惑
1435
0
7




关于分布式应用的一点疑惑
626
0
2


关于去重的两点疑惑
1253
0
1
关于使用 from 子查询替代where子查询疑惑?
1051
1
6


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











