请问老师,seq2seq模型怎么把输入的不定长句子转化成定长的向量啊?
是通过给encoder中的LSTM设置固定的神经元吗?
还有一个不明白的是,比如LSTM有四个神经元,那输入的句子假如是“大家早上好”,这里有五个字,那应该怎么输入啊?
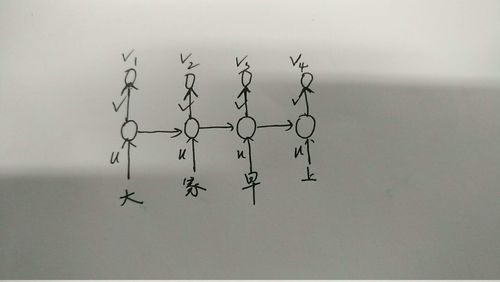
像这样吗?那“好”怎么输入?
最后,是不是v1,v2,v3,v4这四个值就直接做一下层网络的输入啦?
2214
收起
正在回答
1回答

相似问题
切割和向量化有什么关系?切割的规则如何设定?
661
0
5


老师请问,有些书里说的向量的范数,是不是指的向量在对应空间中的模?
1224
1
4


请教老师:怎样定位时间序列中的特定子序列(具体描述点击看图)
754
0
3




登录后可查看更多问答,登录/注册




