内容管理平台数据抓取,深度优先模式抓取问题
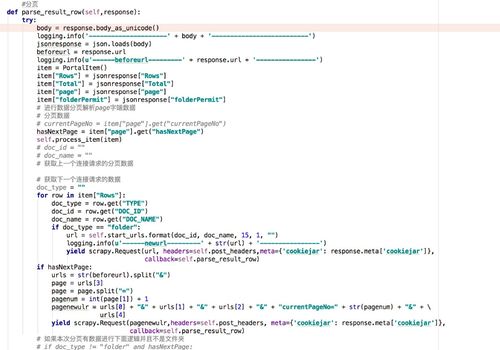
老师我想爬一个公司内部的内容管理系统,内容管理系统URL格式是这样的:http://10.156.0.129/hbcmp/documentList.action?folderId={0}&folderNamePath={1}&pageSize={2}¤tPageNo={3}&keyword={4}
其数据结构是树型带有子节点,我用到递归遍历,我的思路就是先模拟登陆,登陆之后就调用内容管理的url地址,得到是一个json数据,然后我解析json数据,获取到json数据之后在修改url地址里面的参数然后在进行爬,也就是想深度优先,可是不知道哪里出了问题,数据一直爬不全,每次运行一次数据会增加一点,我入库的时候也查询了数据,相同的不进行入库。请老师帮我看看,谢谢!
1224
收起
正在回答 回答被采纳积分+3
3回答




相似问题
无法抓取的一个内容
765
0
2


老师比如我想动态获取美团美食的数据动态抓取到网页之后还怎么处理呢
983
0
6


请问下学完该视频可以抓取美菜网的app数据不
943
0
3


抓取这种招聘网站会有风险吗?
1561
0
3
直播数据抓取?
1704
0
4


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











