为什么redis服务会给我返回一个空的结果,导致redis服务关闭
运行crawl爬虫,socket返回空字符串,redis服务就关闭了,根本爬取不了呀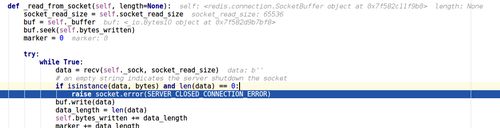
2159
收起
正在回答
8回答


相似问题
请问微服务系统里面,Redis一般是以什么方式提供服务的
894
1
2


关于云服务器上的redis
1199
2
10


redis在本地运行的时候可以用,使用服务器上运行时会报错
1192
0
6


redis服务器地址
1629
0
6


Redis相关问题
1151
0
3
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











