关于 Adaboost 与 GBDT 加权操作疑问
老师好,我最近对这两种集成算法存在不少疑惑。
这两者都属于 boosting 算法,整体而言的步骤如下:
1.初始样本权重一致;
2.构建第一个学习器后,第二个学习器会增大【第一轮】分错样本的权重,减小【第一轮】分对样本权重;
3.第n个学习器会增大【第n-1轮】分错样本的权重,减小【第n-1轮】分对样本权重;
4.重复3步骤;
5.对m个学习器进行加权投票。
我的问题有:
1.重复3步骤后,遇到什么情况会停止?
2.加权投票是什么意思,怎么加权?(分类准确率高的学习器权重增大?)
如上是一些原理的不理解,如下是 Adaboost 与 GBDT 的疑惑。
adaboost
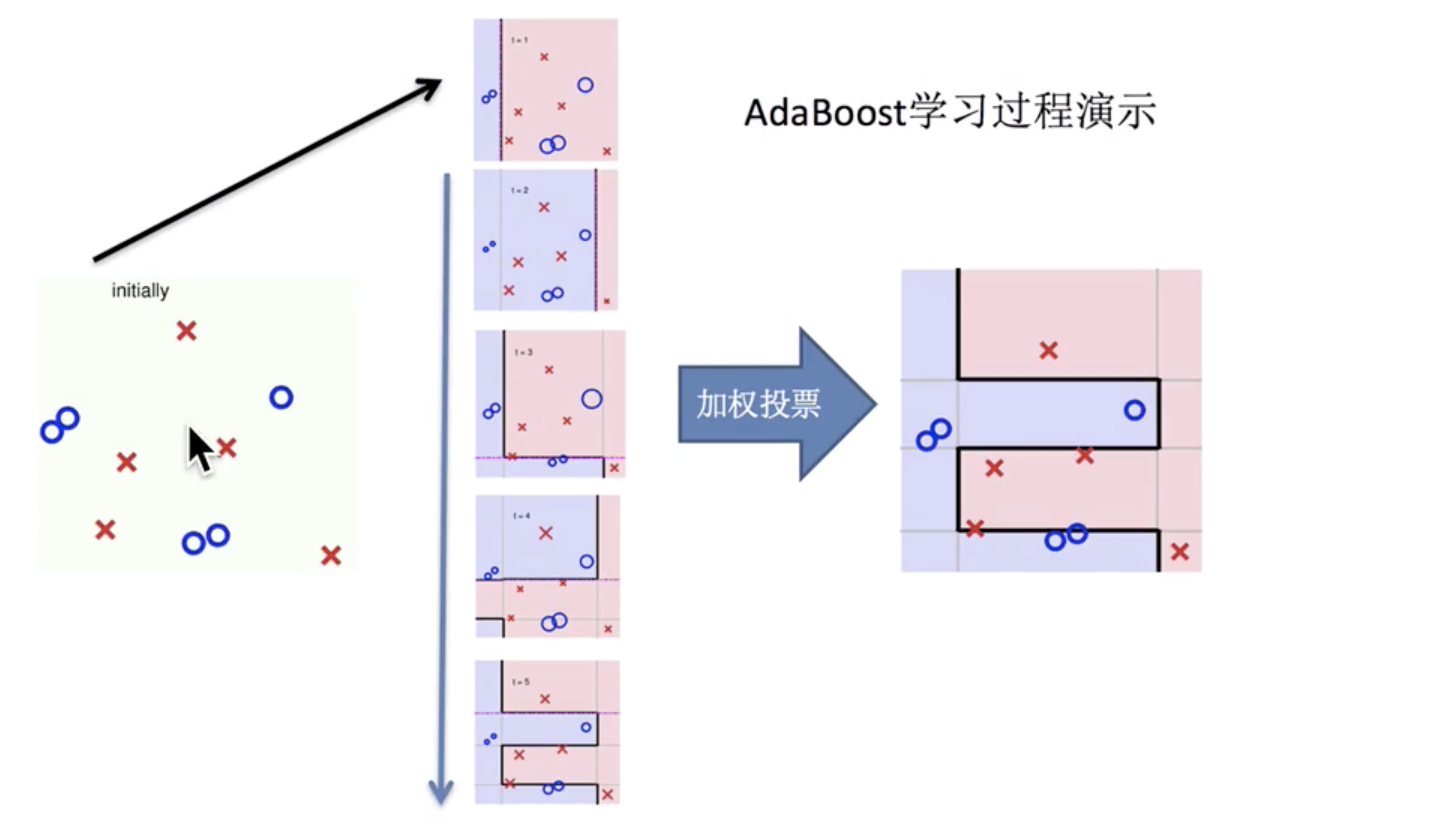
我网上找了一张图,如下所示,每一个学习器增大上一轮学习器分错样本的权重,减小上一轮学习器分对样本的权重。
我的问题是:
3.下图看起来是分类问题,如果解决回归问题,还能加权投票的?具体是如何来预测相应的回归数值的?
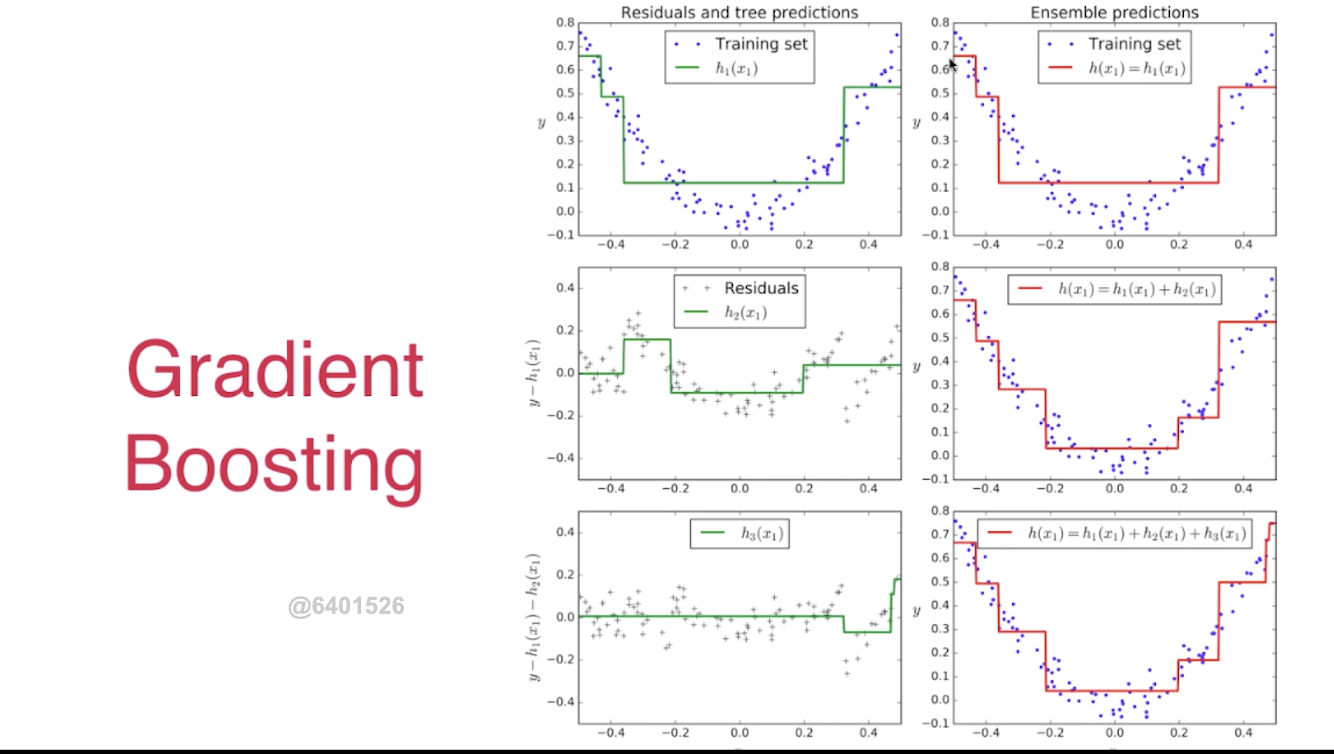
GDBT
GDBT 解决回归问题,老师已经给了样例图,我是比较好理解的。
即 GDBT 的每个子学习器,根据预测值与实际值产生的偏差来训练模型,进而逐步使偏差减小,最后通过加权方式,输出预测结果。
我的问题是:
4.整个GDBT算法逻辑,感觉与boosting 初始样本权重一致,后续增大错误样本权重,减小准确样本权重的步骤不太一致,是否boosting 单指 adaboost?
5.GDBT 解决回归问题,我是很好理解的。但解决分类问题,我是比较难以想象的。他采取的方式,是否借鉴逻辑回归?这里的分类问题,是否有加权操作,如何加权操作?
1611
收起
正在回答
1回答
相似问题
我有个角色roles和菜单menus关联关系的问题
1260
0
5


权限问题
1424
0
3


adaboost里面样本的权重
1116
2
1


老师 关于权限 角色 用户之间的关系
1504
0
3
关于操作数栈、操作栈和虚拟机栈和程序计数器
2435
0
5


登录后可查看更多问答,登录/注册








