采集的数据存储问题。
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from urllib import parse
import re
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import DNSLookupError
from twisted.internet.error import TimeoutError, TCPTimedOutError
import time
from datetime import datetime
from orderspider.items import orderrankitem
class RankingSpider(scrapy.Spider):
name = 'ranking'
allowed_domains = ['amazon.com']
# start_urls = ['https://www.amazon.com/b/ref=sr_aj?node=1045024&bbn=1040660&ajr=0']
start_urls = ['https://www.amazon.com/s/ref=lp_1040660_ex_n_2?rh=n%3A7141123011%2Cn%3A7147440011%2Cn%3A1040660&bbn=7147440011&ie=UTF8']
def parse(self, response):
cate_nodes = response.xpath('//*[@id="leftNav"]/ul[1]/ul/li/span/ul/div/li/span/li/span/ul/div//li//a')
for list_url in cate_nodes:
categorys_url = list_url.xpath('@href').extract_first("")
categorys_name = list_url.xpath('span/text()').extract_first("")
yield scrapy.Request(url=parse.urljoin(response.url, categorys_url),
meta={"categorys": categorys_name},
callback=self.parse_list, errback=self.errback_http,
dont_filter=True)
def parse_list(self, response):
post_nodes = response.xpath('//*[contains(@id,"result_")]/div/div[3]/div[1]')
for post_url in post_nodes:
good_url = post_url.xpath('a/@href').extract_first("")
title = post_url.xpath("a/h2/text()").extract_first("")
sku_str = '/dp/(.+)/ref'
sku_obj = re.search(sku_str, good_url)
if sku_obj:
sku = sku_obj.group(1)
regex_str = 'sr=(.+)&nodeID'
match_obj = re.search(regex_str, good_url)
if match_obj:
good_rank = match_obj.group(1).replace("1-", "")
good_ranks = int(good_rank)
yield scrapy.Request(url=parse.urljoin(response.url, good_url),
meta={"rank_good": good_ranks, "sku": sku, "title": title, "categorys": response.meta.get("categorys" "")},
callback=self.parse_detail, errback=self.errback_http,
dont_filter=True)
time.sleep(1)
next_url = response.css("#pagnNextLink.pagnNext::attr(href)").extract_first("")
if next_url:
print(next_url + '%s'.format("下一页"))
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse,
dont_filter=False)
def parse_detail(self, response):
order_rank = orderrankitem()
time.sleep(1)
intime = datetime.now().strftime('%Y-%m-%d')
fit = response.css('#fitRecommendationsLinkRatingText::text').extract_first(default="20%").strip().replace("As expected (", "").replace(")", "")
asterisk = response.xpath('//*[@id="acrPopover"]/span[1]/a/i[1]/span/text()').extract_first(default="0").strip().replace(" out of 5 stars", "")
reviews = response.xpath('//*[@id="acrCustomerReviewText"]/text()').extract_first()
if reviews:
review_nums = reviews.replace(" customer reviews", "")
else:
review_nums = 0
answered_question = response.xpath('//*[@id="askATFLink"]//span/text()').extract_first()
if answered_question:
an_question = int(answered_question.strip().replace(" answered questions", ""))
else:
an_question = 0
order_rank["rank"] = response.meta.get("rank_good", "")
order_rank["url"] = response.url
order_rank["title"] = response.meta.get("title", "")
order_rank["sku"] = response.meta.get("sku", "")
order_rank["in_time"] = intime
order_rank["fit"] = fit
order_rank["asterisk"] = asterisk
order_rank["categorys"] = response.meta.get("categorys", "")
order_rank["review_nums"] = review_nums
order_rank["an_question"] = an_question
yield order_rank
def errback_http(self, failure):
self.logger.error(repr(failure))
if failure.check(HttpError):
# these exceptions come from HttpError spider middleware
# you can get the non-200 response
response = failure.value.response
self.logger.error('HttpError on %s', response.url)
elif failure.check(DNSLookupError):
# this is the original request
request = failure.request
self.logger.error('DNSLookupError on %s', request.url)
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.error('TimeoutError on %s', request.url)
老师这是我的代码 ,有个问题想请教你一下, 当我数据采集到第三层的时候, 保存的数据总会随机的保存不了,保存了我传进去的默认值。我做了爬虫延时和限速, 但是都没有达到预期效果,没有做ip代理, 设置了请求头, 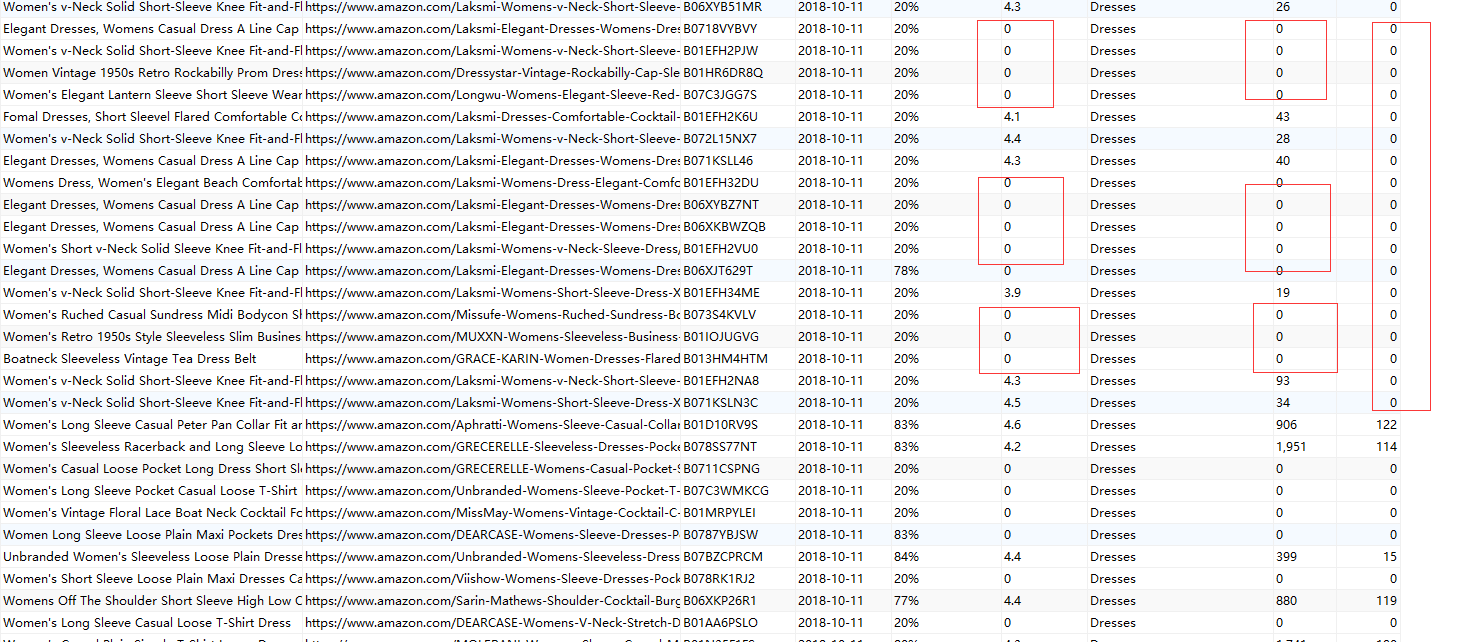
请老师忙我看下,这个是什么原因造成的。
325
收起
正在回答 回答被采纳积分+3
1回答

相似问题
exporter采集的数据流向问题
595
1
3




关于PXC集群模式中,mysql配置的定时任务事件如何执行的问题
802
0
4


再问一个终极问题
476
0
6




node exporter采集数据的三种方式
1226
1
4
老师聚集索引和非聚集索引的ppt 内容,图片和老师的讲解, 不太理解
1028
0
3


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











