crawlspider中能yield出去 Request的吗?
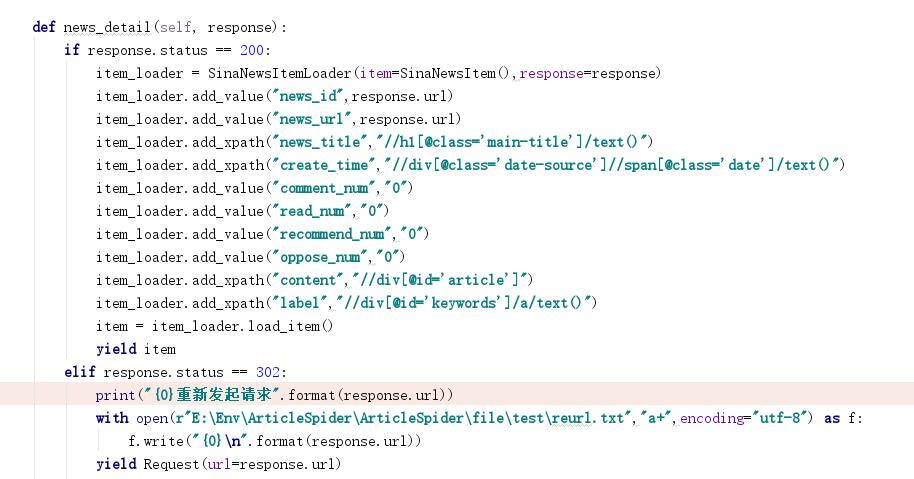
老师您好,如上图,我设置了status为302的url返回我再一次处理,按照道理只要这个url返回的状态是302的都会被处理,实施证明了也进入了这个函数,我把url写入了一个文件,我等到scrapy没有页面可爬的时候在elasticsearch中搜索这些url没发现写入数据,所以我就有疑问,我这样写对吗?
1024
收起
正在回答
1回答
相似问题
yield 和 return的问题
1667
0
3


ScrapyRedis Crawl不会继续爬取
1237
0
8


请问CrawlSpider中可以使用request的meta来传递参数么
1242
0
2


老师我debug一直重复这yield一条,进不去parse_nums
1075
0
4
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











