无法使用Spark来访问Hive
package com.imooc.bigdata.chapter06
import java.util.Properties
import org.apache.spark.sql.SparkSession
object HiveSourceApp {
def main(args: Array[String]): Unit = {
// 如果你想使用Spark来访问Hive的时候,一定需要开启Hive的支持
val spark: SparkSession = SparkSession.builder().master("local").appName("HiveSourceApp")
.enableHiveSupport() //切记:一定要开启
.getOrCreate()
// 走的就是连接 default数据库中的pk表,如果你是其他数据库的,那么也采用类似的写法即可
spark.table("default.pk").show()
spark.stop()
}
}
报的是这个错误:
Exception in thread “main” org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: rw-rw-rw-;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:214)
at org.apache.spark.sql.internal.SharedState.externalCataloglzycompute(SharedState.scala:114)atorg.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)atorg.apache.spark.sql.internal.SharedState.globalTempViewManagerlzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
at org.apache.spark.sql.internal.SharedState.globalTempViewManagerlzycompute(SharedState.scala:114)atorg.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)atorg.apache.spark.sql.internal.SharedState.globalTempViewManagerlzycompute(SharedState.scala:141)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:136)
at org.apache.spark.sql.hive.HiveSessionStateBuilderKaTeX parse error: $ within math modeanonfun$2.apply(HiveSessionStateBuilder.scala:55)
at
看老师视频上直接连上去了,就能输出PK表里面的数据,我这个报的超时错误,说HDFS上应该需要写权限,我就把HDFS中的tmp目录赋777的权限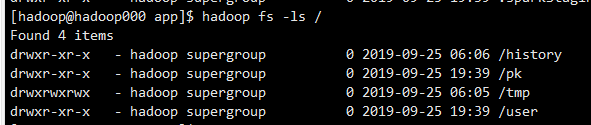
然后还是连不上去,我就去百度搜了搜,把windows上的也改成777了,结果还是连不上去,请老师指导,老师辛苦
正在回答 回答被采纳积分+3
2回答
相似问题




登录后可查看更多问答,登录/注册









