有HBase之后为什么还需要KUDU
在google上查找的资料,对我而言比这篇文章https://yq.aliyun.com/articles/363661相对更好理解些。
HDFS和HBase是大数据最常用的两种存储方式,它们的优缺点非常明显:
HDFS,使用列式存储格式Apache Parquet,Apache ORC,适合离线分析,
不支持单条记录级别的update操作,随机读写性能差。这个就不多说了,用过HDFS的同学应该都知道这个特点。
HBase,可以进行高效随机读写,却并不适用于基于SQL的数据分析方向,大批量数据获取时的性能较差。
那为什么HBase不适合做分析呢?
因为分析需要批量获取数据,而HBase本身的设计并不适合批量获取数据
1)都说HBase是列式数据库,其实从底层存储的角度来说它并不是列式的,获取指定列数据时是会读到其他列数据的。
相对而言Parquet格式针对分析场景就做了很多优化。
2)HBase是LSM-Tree架构的数据库,这导致了HBase读取数据路径比较长,从内存到磁盘,可能还需要读多个HFile文件做版本合并。
LSM 的中心思想就是将随机写转换为顺序写来大幅提高写入操作的性能,但是牺牲了部分读的性能。
随机读写是指对任意一个位置的读和写,磁盘随机读写慢是因为需要寻道,倒带才可以访问到指定存储点,而内存不需要,可以任意指定存储点
为了让数据平台同时具备随机读写和批量分析能力,传统的做法是采用混合架构(hybrid architecture),也就是我们常说的T+1的方式,数据实时更新在HBase,第二天凌晨同步到HDFS做离线分析。这样的缺点很明显,时效性差,数据链路长,过程复杂,开发成本高。
这个时候Kudu出现了,它是介于HDFS和HBase两者之间的一个东西,如下图所示,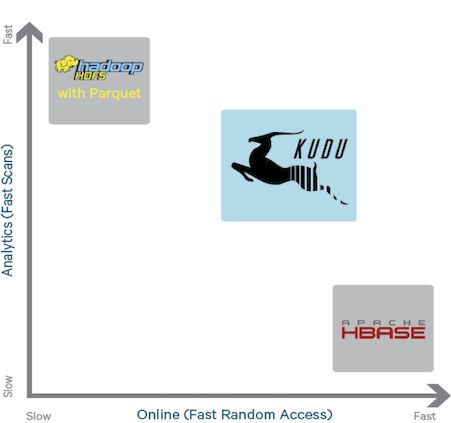
它不及HDFS批处理快,也不及HBase随机读写能力强,但是反过来它比HBase批处理快(适用于OLAP的分析场景),而且比HDFS随机读写能力强(适用于实时写入或者更新的场景),这就是它能解决的问题。
正在回答
1回答

相似问题




登录后可查看更多问答,登录/注册









