异步写入mysql的时候,在保存成功时候我想回调一下成功的addCallback,发现部署到linux后不生效

一开始 , 发现在windows开发环境 ,直接运行程序 不会走进 成功回调 函数 ,
当在爬虫的 def close 方法里 休了几秒后 ,可以进入 成功回调函数,
但是 当我 部署到 linux 的 scrapyd 环境后 发现 成功回调函数 不会进去 , 即使 加大了休眠时长 .
现在业务 需求 , 在插入这条数据后, 要发送 requests.post()请求 调用一下 另一个接口 作为触发条件 .
1205
收起
正在回答 回答被采纳积分+3
2回答

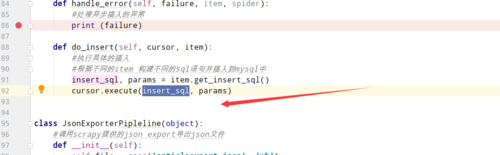 你可以把逻辑写在这里啊
你可以把逻辑写在这里啊相似问题







登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











