基于size优化和基于rank优化的对比
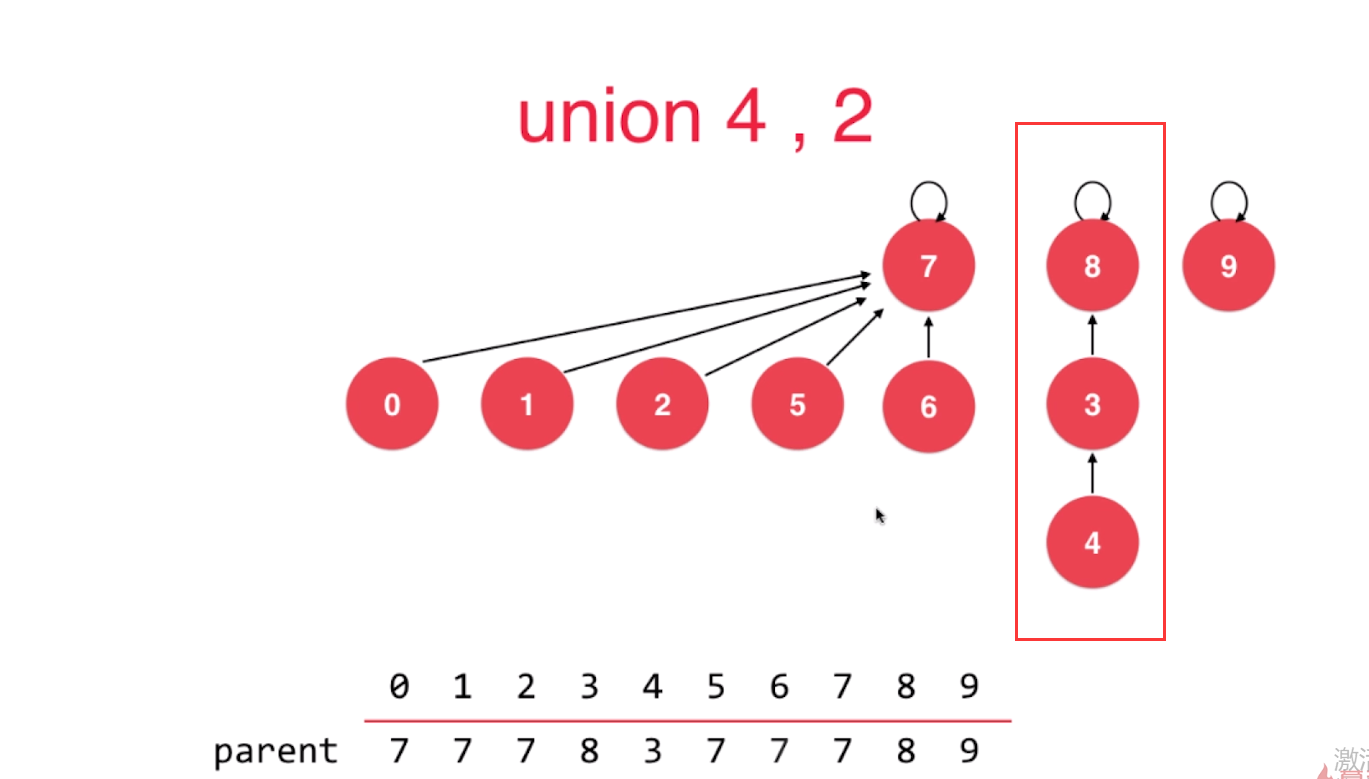
如果采用基于size的优化, 4->3->8是不可能的吧, 基于size优化后三个元素应该是
a -> c <- b的形式吧
基于size优化后,对于森林中的每棵树,当树的节点数size>=3时,这棵树是不会退化为链表形式的吧,每棵树都会有几个分叉吧。
有一点不是太理解
基于size优化是不是因为
假设:树a的结点数 > 树b的结点数,也就意味着树a的深度“很大概率”上比树b的深度要大(应该不是100%,但是我举不出来反例,求bobo老师举个例子),所以将结点数少的集合并入到结点数多的集合。
所以基于size优化和基于rank优化的时间上,rank略小于size吧,因为size不是100%判定正确的,也可能深度大的树并到了深度小的树。
1628
收起
正在回答
1回答
相似问题
老师,基于size的优化有什么不适用的场景吗?
1173
0
4


Size 优化 Rank优化对比疑问
1119
6
1
视频中的疑问,基于size优化后,8←3←4这个树可能出现吗?
828
2
1
volatile标记的变量不会被优化,这里指的是什么意思
1662
0
3


老师,最优化原理和凸优化什么区别的?
5426
1
7
登录后可查看更多问答,登录/注册



