采用selenium爬取拉勾
用crawlspider写的爬取拉钩的程序
看了关于selenium的章节,将selenium集成到scrapy,然后仿照着写了一些逻辑,希望老师指点下
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/']
rules = (
Rule(LinkExtractor(allow=('zhaopin/.*',)),follow=True),
Rule(LinkExtractor(allow=('gongsi/v1/j\d+.html',)),follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_job', follow=True),
)
def __init__(self):
chrome_option = Options()
chrome_option.add_argument("--disable-extensions")
chrome_option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
self.broswer = webdriver.Chrome(executable_path="D:/pythonProject/ArticleSpider/chromedriver.exe",
chrome_options=chrome_option)
super(LagouSpider, self).__init__()
try:
self.broswer.maximize_window()
except:
pass
self.fail_urls = [] # 创建一个变量来储存404URL
self.url = 'https://passport.lagou.com/login/login.html'
self.cookies_dict = {}
self.cookies = []
dispatcher.connect(self.handle_spider_closed, signals.spider_closed)
def handle_spider_closed(self, spider, reason):
self.crawler.stats.set_value("failed_urls", ",".join(self.fail_urls))
def login(self):
def parse(self, response):
"""
1. 获取文章列表页中的职位url并交给scrapy下载后并进行解析
2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse
"""
# 解析列表页中的所有职位url并交给scrapy下载后并进行解析
def start_requests(self):
# 从文件中读取cookie
yield scrapy.Request(self.broswer.current_url, dont_filter=True,cookies=self.cookies_dict,headers=self.headers)
def parse_job(self, response):
# 解析拉勾职位信息
middleware中
class JSPageMiddleware:
# 通过chrome请求动态网页
def process_request(self, request, spider):
if spider.name == "lagou":
spider.browser.get(request.url)
time.sleep(3)
print("访问:{0}".format(request.url))
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source,encoding="utf-8", request=request)
报错信息
2021-03-22 20:50:20 [scrapy.core.scraper] ERROR: Error downloading <GET https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=>
Traceback (most recent call last):
File "D:\pythonProject\venv\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "D:\pythonProject\venv\lib\site-packages\scrapy\core\downloader\middleware.py", line 36, in process_request
response = yield deferred_from_coro(method(request=request, spider=spider))
File "D:\pythonProject\ArticleSpider\ArticleSpider\middlewares.py", line 127, in process_request
spider.browser.get(request.url)
**AttributeError: 'LagouSpider' object has no attribute 'browser'**
2021-03-22 20:50:20 [scrapy.core.engine] INFO: Closing spider (finished)
2021-03-22 20:50:20 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 1,
'downloader/exception_type_count/builtins.AttributeError': 1,
'elapsed_time_seconds': 0.219971,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 3, 22, 12, 50, 20, 814227),
'log_count/DEBUG': 10,
'log_count/ERROR': 1,
'log_count/INFO': 10,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2021, 3, 22, 12, 50, 20, 594256)}
2021-03-22 20:50:20 [scrapy.core.engine] INFO: Spider closed (finished)
主要是AttributeError: ‘LagouSpider’ object has no attribute 'browser,是不是因为用的是crawlspider的原因呢,难道一定要用scrapy.Spider写爬虫程序?
我新建了继承scrapy.Spider的爬虫.py,调试发现和之前用crawlspider一样,到这一步再向下单步调试就卡住了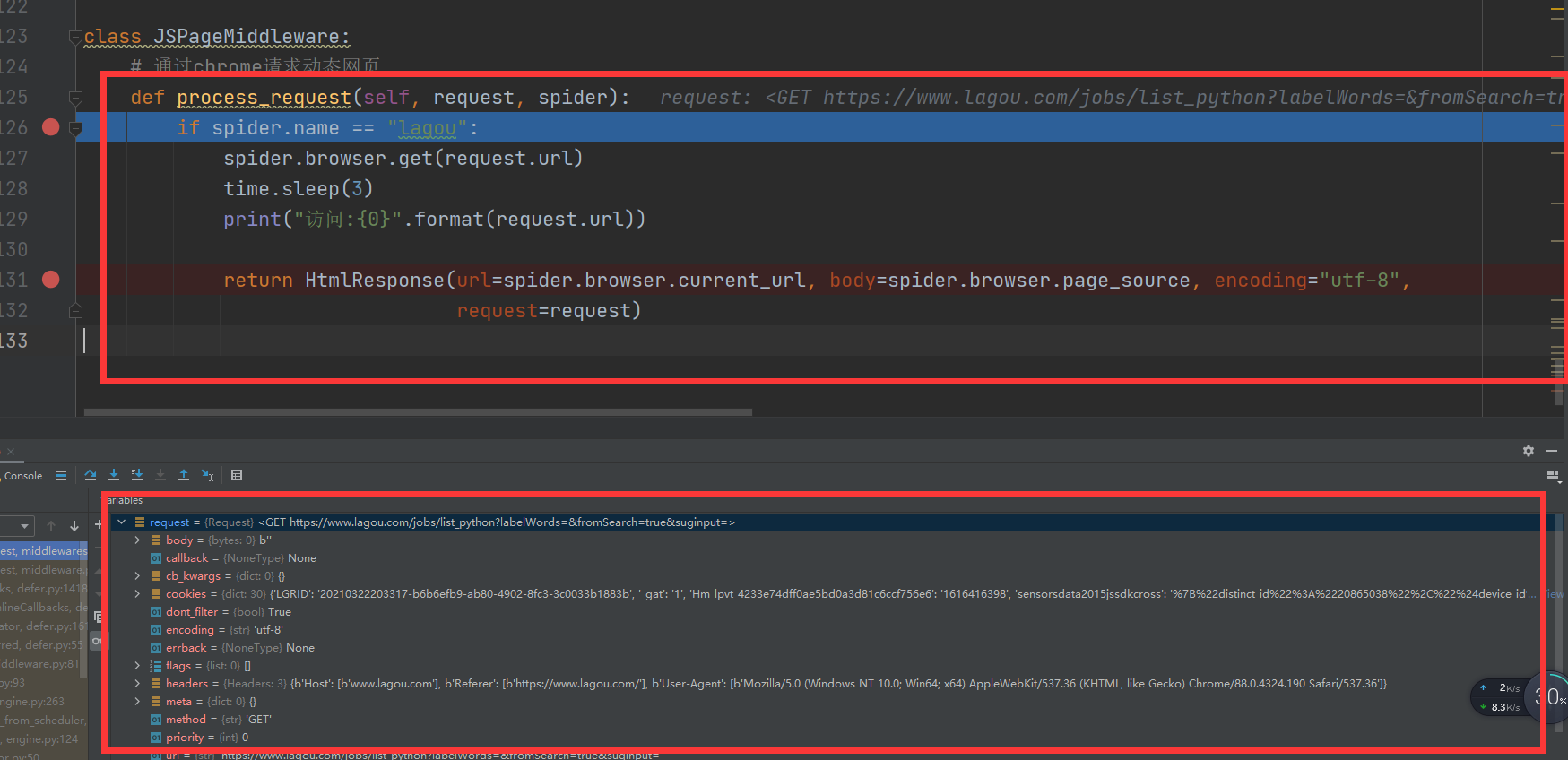
之前和老师在QQ上交流说,可以用selenium来爬取拉钩的,但是尝试很长时间,遇到种种问题让我摸不到头绪,毕设比较着急,老师可以帮忙解决下吗
1481
收起
正在回答
2回答

相似问题
无法爬取拉勾职位详情页
810
0
1


爬取拉钩要登录
1585
0
2


老师现在拉勾网的反爬策略是什么呢?
1364
0
3
Scrappy shell无效
942
0
3
爬取拉钩老是被重定向,
1100
0
14
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











