Caused by: java.net.UnknownHostException: hadoop000
from pyspark import SparkConf, SparkContext
import os
# os.environ['JAVA_HOME'] = 'C:\Program Files\Java\jdk-16.0.1'
# 创建SparkConf:设置的是Spark相关的参数信息
conf = SparkConf().setMaster("local[2]").setAppName("spark0301")
# 创建 SparkContext
sc = SparkContext(conf=conf)
# 业务逻辑
data = [1 ,2 ,3, 4, 5]
distData = sc.parallelize(data)
print(distData.collect())
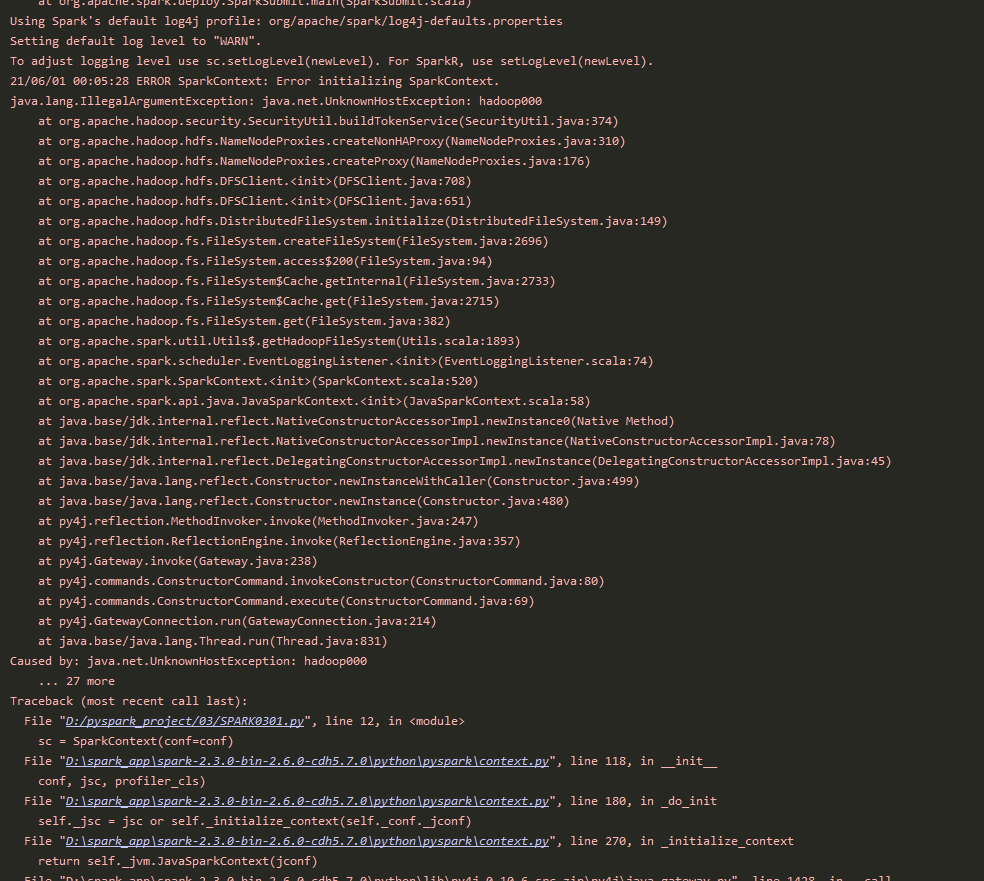
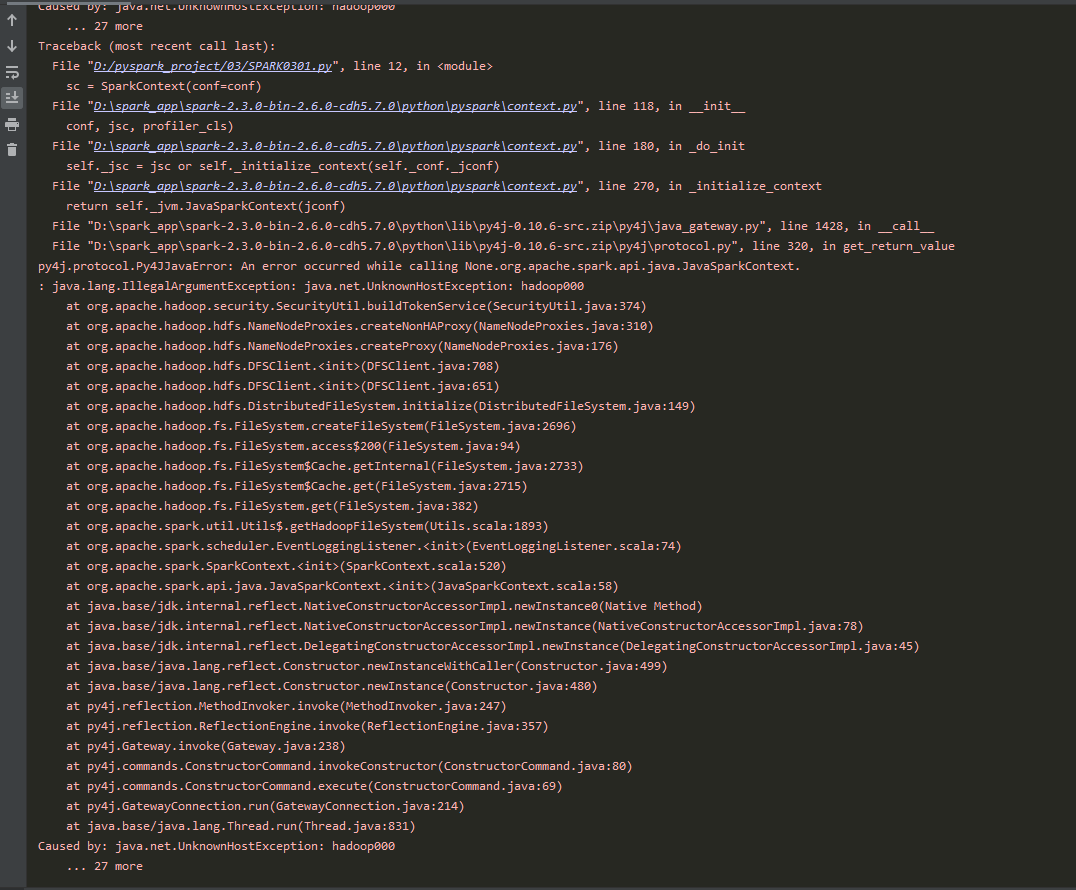
老师,实在是搞不明白这里为什么出问题了
1562
收起









