import requests
from lxml import html
def spider(sn):
url = 'https://search.jd.com/Search?keyword={0}'.format(sn)
resp = requests.get(url)
resp.encoding = 'utf-8'
# print(resp.encoding)
html_data = resp.text
selector = html.fromstring(html_data)
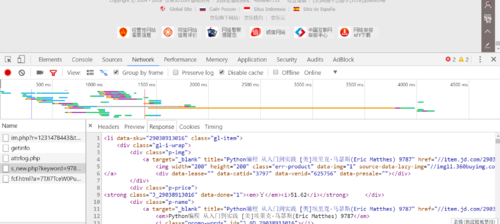
ul_list = selector.xpath('//div/ul[@class="gl-warp clearfix"]/li')
# print(len(ul_list))
# ul_list = selector.xpath('//div[@id="J_goodsList"]/ul/li')
#
print(len(ul_list))
for li in ul_list:
title = li.xpath('div/div[@class="p-name"]/a/@title')
print(title[0])
link = li.xpath('div/div[@class="p-name"]/a/@href')
print(link[0])
price = li.xpath('div/div[@class="p-price"]/strong/i/text()')
print(price[0])
provider = li.xpath('div/div[@class="p-shopnum"]/a/@title')
print(provider[0])
print('-----------------')
if __name__ == '__main__':
spider('9787115428028')