deepseek模型分词中文丢失
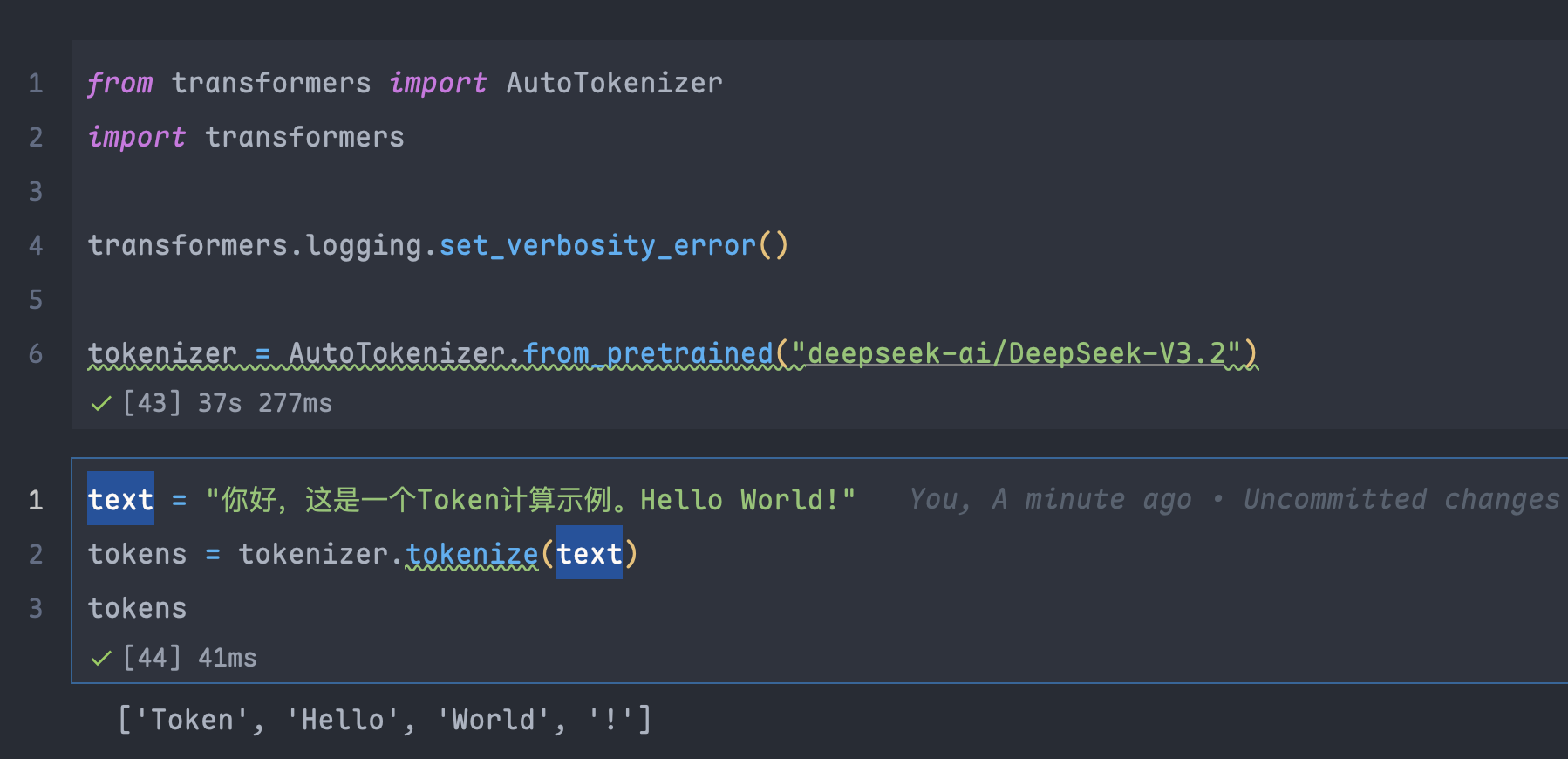
上面使用 deepseek-v3.2模型,分词结果中文丢失了,使用 deepseek-v3 版本也是一样的,我看老师你讲课过程中是直接能够输出结果的,是我这边缺少了什么设置吗?
环境信息:
transformers=5.3.0
Python=3.12.13
14
收起
正在回答 回答被采纳积分+3
2回答

相似问题

请教老师 结巴分词 能实现英文单词分词吗?
1015
0
4


老师,有对接deepseek课程吗
326
0
5


新建分支,git pull之后本地代码丢失
2492
0
3


prisma文件可以拆分多个模型文件吗
214
0
4


登录后可查看更多问答,登录/注册




