请问,为什么spark-sql里show tables有表,spark-submit提交job里没有表?
因为课程里都是用 spark-sql --master local[2] 本地模式来操作的,我这边尝试用 spark://hadoop-web:7077 连接后发现有些问题
spark-sql --master spark://hadoop-web:7077
show tables
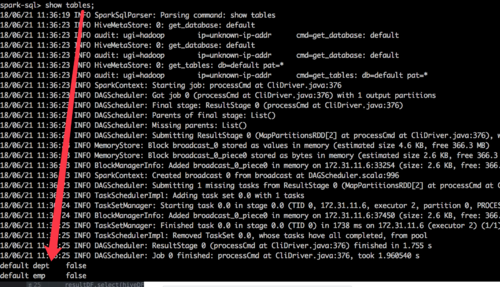
有表数据,但是我在scala上:
val spark = SparkSession.builder().appName("HiveMysqlApp").master("spark://hadoop-web:7077").getOrCreate()
spark.sql("show tables").show()
本地执行后,一直没有结果:
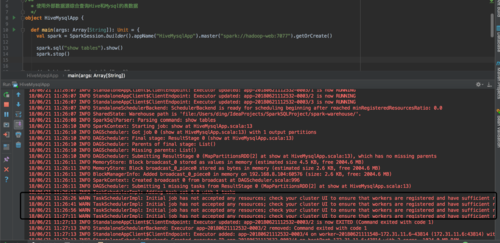
18/06/21 11:27:26 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
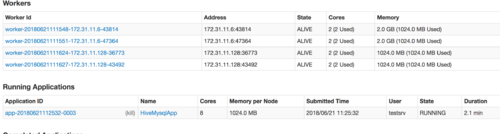
看样子是在申请资源,看了他的状态是RUNNING,并不是WAITING。
然后我用 mvn clean package -DskipTest 把jar包放在虚拟机里面用:
[hadoop@hadoop-web bin]$ ./spark-submit --class com.spark.HiveMysqlApp --master spark://hadoop-web:7077 /home/hadoop/jar/sql-1.0.jar
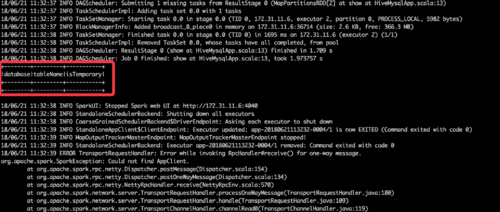
又没有表了,请问这个是怎么回事?
2045
收起
正在回答 回答被采纳积分+3
1回答
相似问题
pyspark可以访问hive但spark-submit访问不了hive
1925
0
3






spark
spark
1436
0
3
PyCharm 本地运行找不到spark-submit
1095
0
3
关于spark application的理解
1808
0
5
spark 写ES报错
1546
0
10


登录后可查看更多问答,登录/注册



