UF1和UF2的比较
在数据量为10000的时候,UF1的时间是UF2的时间的接近4倍,但是数据量为10000的时候,UF2的时间反而增加了,请问bobo老师这个原因是为什么呢?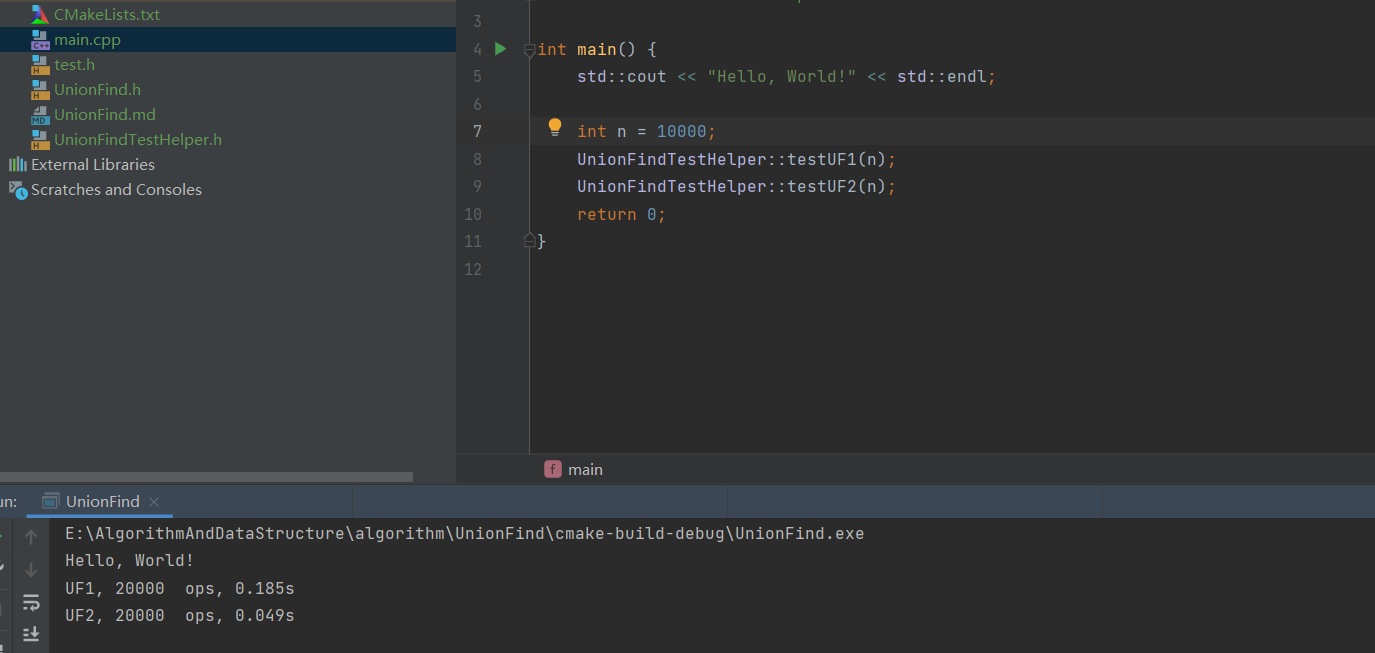
// 查找过程, 查找元素p所对应的集合编号
int find(int p){
assert( p>=0 && p<=count );
return id[p];
}
// 查看元素p和元素q是否所属一个集合
// O(1)复杂度
bool isConnected(int p,int q){
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(n) 复杂度
void unionSet(int p,int q){
int pId = find(p);
int qId = find(q);
if(pId == qId)
return;
// 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并,就是合并两个集合
for(int i=0;i<count;i++){
if(id[i]==pId)
id[i]=qId;
}
}
int find(int p){
assert(p>=0&&p<=count);
while(p!=parent[p])
p = parent[p];
return p;
}
bool isConnected(int p,int q){
return find(p) == find(q);
}
void unionSet(int p,int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}
备注:这里我将UF1和UF2的类放在同一个头文件UnionFind中,用不同的命名空间分开,没有像你给的代码一样两个放在不同头文件,后来我尝试将其放在两个头文件,其运行结果和放在一个文件的差不多,应该不是这个原因。
1590
收起
正在回答
1回答
相似问题
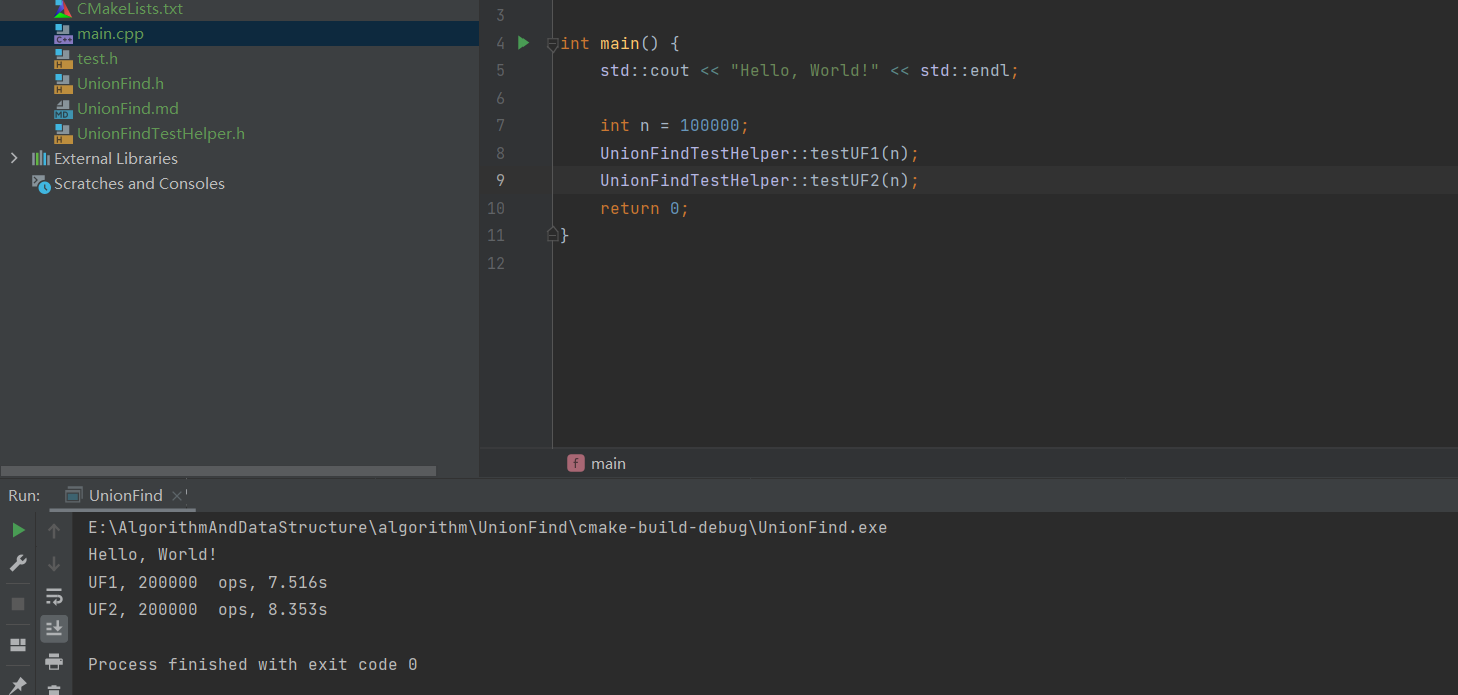
在windows系统下,n=100000时,UF1所用的时间小于UF2
1132
0
6




UF2效率非常低
935
1
2

tag 和key相同,不再进行深度比较
1443
1
6






为什么用java实现时要比老师用C++实现时要快一个量级的时间呢?
1067
0
1
登录后可查看更多问答,登录/注册








