压缩和未压缩的文件大小没有区别
使用的chrome浏览器,比较了压缩前和压缩后的文件,没有大小上的改变。有的甚至压缩后比未压缩的还要大一点点。不知道为什么。
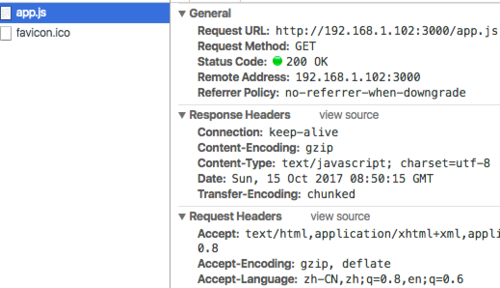
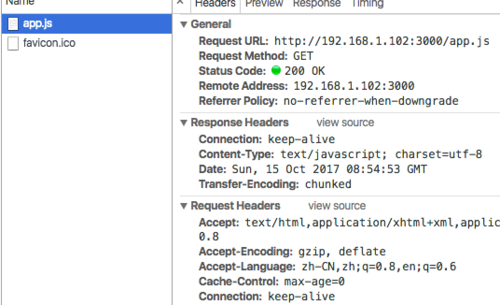
是因为chrome浏览器自带就有压缩功能吗?
2091
收起
正在回答 回答被采纳积分+3
6回答




相似问题
压缩后文件变大
1472
0
4


读取压缩文件乱码
899
0
3


路径压缩的问题
1511
1
1


老师,您的源码哪里还有呢?我在下载标签下下载的zip格式文件都解压不了
1182
0
4




yii2的压缩包在哪?
935
0
3




登录后可查看更多问答,登录/注册




