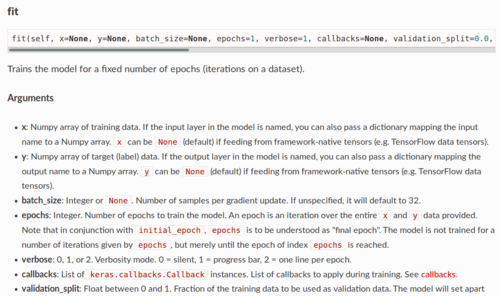
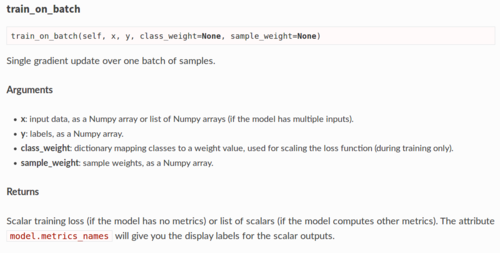
output_batch是输入给训练函数的label吗,它与model.fit函数中的label表示含义是一样的吗,为什么程序中要那么定义
output_batch = [1] * BATCH_SIZE + [0] * BATCH_SIZE
#训练判别器, 让它具备识别不合格生成图片的能力
d_loss = d.train_on_batch(input_batch, output_batch)
1841
收起
正在回答
1回答

相似问题
为什么子类的构造函数中需要传入父类的参数
2087
1
7




如何定义一个泛型函数,求和
1378
0
4


子类定义了新的构造函数以后,父类的构造函数就不会被执行了吗?
1447
0
2
请问自定义损失函数的输入如果是多维的应该怎么写呢?
1941
0
6




训练数据集就是模型?还是kNN是模型?
2183
2
11




登录后可查看更多问答,登录/注册
本课精华内容
问答
在转换成逻辑矩阵时出错zero-size array to reduction operation maximum which has no identity
17.1k 10

老师好,能否增加一块讲解内容,讲解一下在windows环境下和linux环境下安装和配制tensorflow开发环境的课程
2.0k 9

安装tensorflow 显示没有合适的版本
1.9k 8

photoshop的train.py不能保存模型文件:generator_weight
2.1k 7
请问一下,我从virtualbox导入课程提供的IMOOC.vdi虚拟机文件,为什么进去之后全是命令行视图,不像课程里讲的那样有界面的
1.7k 7