因为抓取得html数据不全root_htmls为空
我调试查看了一下抓取到的网页数据, 为什么我抓取到的网页数据不全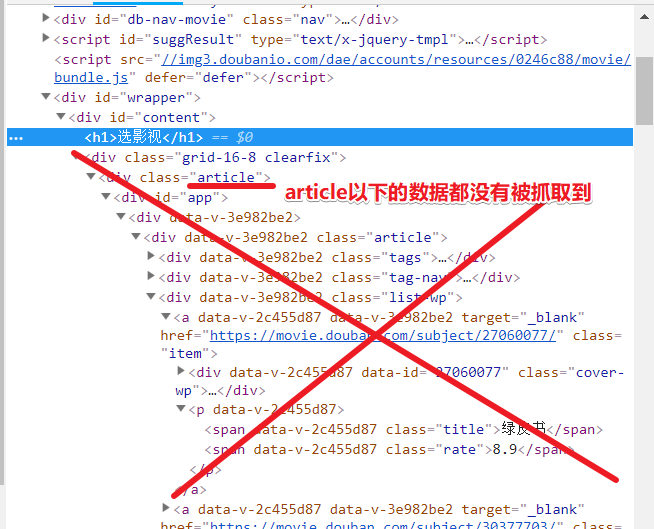
import re
from urllib import request
class Spider():
url = "https://movie.douban.com/tag/#/?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1,%E5%96%9C%E5%89%A7"
urlpartten = 'article'# 用最简单的匹配 只能匹配到article级别
def __fetch_content(self):
r = request.urlopen(Spider.url)
self.htmls = r.read()
self.htmls = str(self.htmls, encoding='utf-8')
return self.htmls
def __analysis(self, html):
root_htmls = re.findall(Spider.urlpartten, html)
print(root_htmls)
def go(self):
html = self.__fetch_content()
self.__analysis(html)
spider = Spider()
spider.go()
1132
收起
正在回答 回答被采纳积分+3
1回答

相似问题
内容管理平台数据抓取,深度优先模式抓取问题
1193
0
6




直播数据抓取?
1693
0
4


rule中follow参数为true。
1039
0
9


抓取这种招聘网站会有风险吗?
1526
0
3
请问下学完该视频可以抓取美菜网的app数据不
930
0
3


登录后可查看更多问答,登录/注册














