采纳答案成功!
向帮助你的同学说点啥吧!感谢那些助人为乐的人
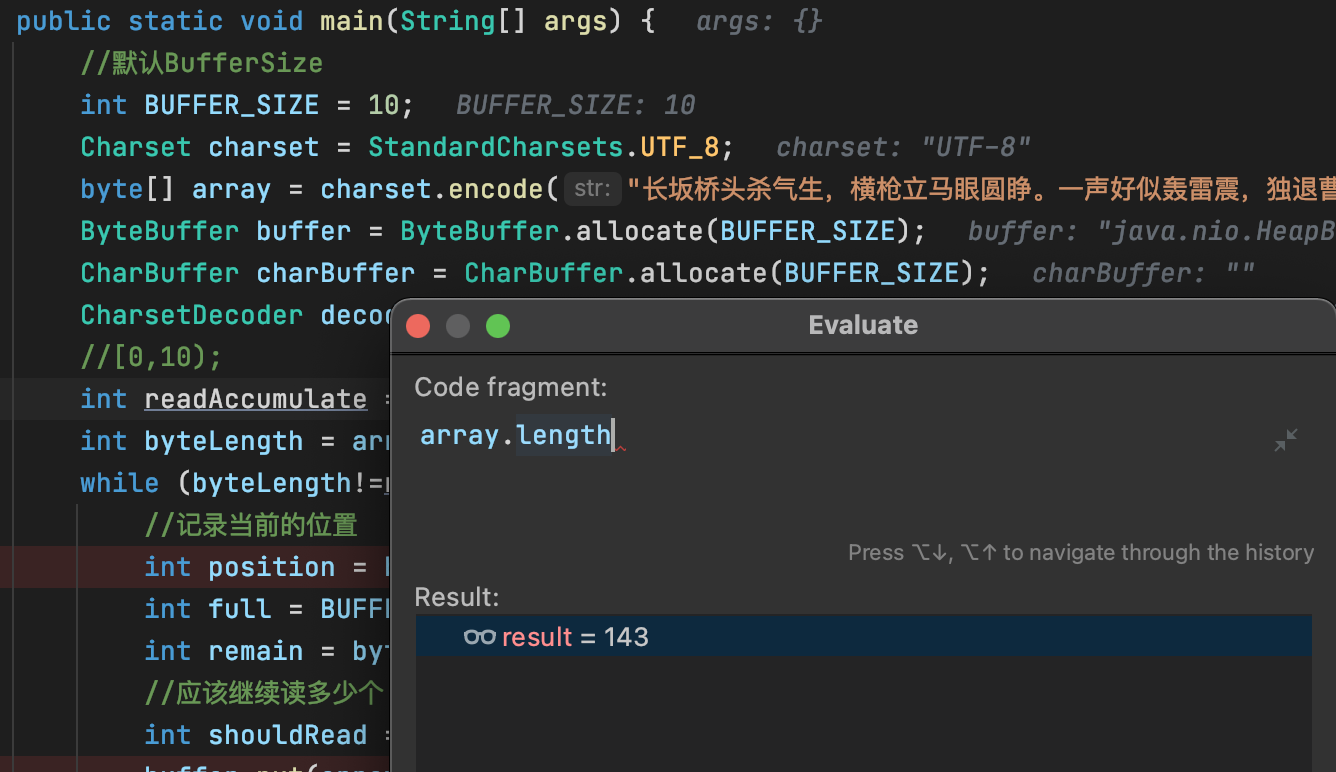
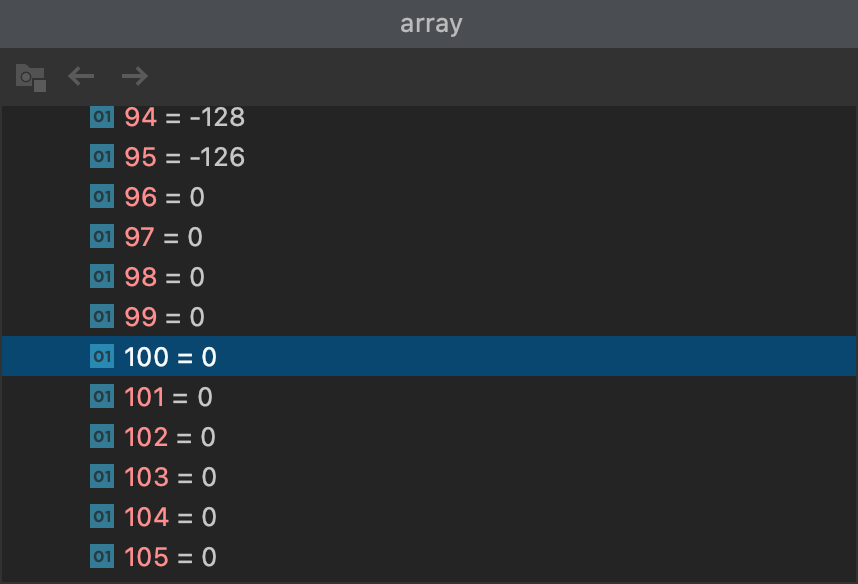
按照老师给出的思路,写了用长度有限的Buffer去循环处理中文乱码,在调试过程中发现一个奇怪的事,就是“长坂桥头杀气生,横枪立马眼圆睁。一声好似轰雷震,独退曹家百万兵。”这句话生产的字节数组长达143字节,而且最后有若干个0,比较奇怪。
虽然这么多的0不影响最终结果的输出,但是对这个0比较有疑问
麻烦再确认下,看上去是buffer没有用完。
上面的截图是charset.encode("长坂坡...").array()的返回结果
查了下源代码,因为java是在不断尝试分配内存转码。每次乘2,冗余系数1.1。感兴趣看下charsetencoder的源代码,见encode函数。
棒,谢老仙,我去理解下
分析下:JVM的开发团队不想为每个CharSet都编写一套算法,于是每个字符到底对应几个byte是不确定的,只有一个个转义。 于是就有了下面这段不断分配的程序。
public final ByteBuffer encode(CharBuffer in) throws CharacterCodingException { int n = (int)(in.remaining() * averageBytesPerChar()); ByteBuffer out = ByteBuffer.allocate(n); if ((n == 0) && (in.remaining() == 0)) return out; reset(); for (;;) { CoderResult cr = in.hasRemaining() ? encode(in, out, true) : CoderResult.UNDERFLOW; if (cr.isUnderflow()) cr = flush(out); if (cr.isUnderflow()) break; if (cr.isOverflow()) { n = 2*n + 1; // Ensure progress; n might be 0! ByteBuffer o = ByteBuffer.allocate(n); out.flip(); o.put(out); out = o; continue; } cr.throwException(); } out.flip(); return out; }
1. 那这个场景下是不是用 raw.getBytes(charset); 更好处理?这个返回的是byte[]长度是96,那charset.encode(raw) 什么时候用,有什么优势 2. 如果用 charset.encode(raw) 来读取,对于这些 0 要怎么判断? 是碰到0就意味着往后的位置不会有数据,可以认为处理结束 return 了么。 (即意味着对于字符串的 byte[] 中间不可能出现0对吧)
登录后可查看更多问答,登录/注册
深度剖析大厂面试高频真题,让你秒变offer收割机
2.0k 6
1.5k 11
1.5k 10
1.3k 10
1.4k 8
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号