关于批量插入作业
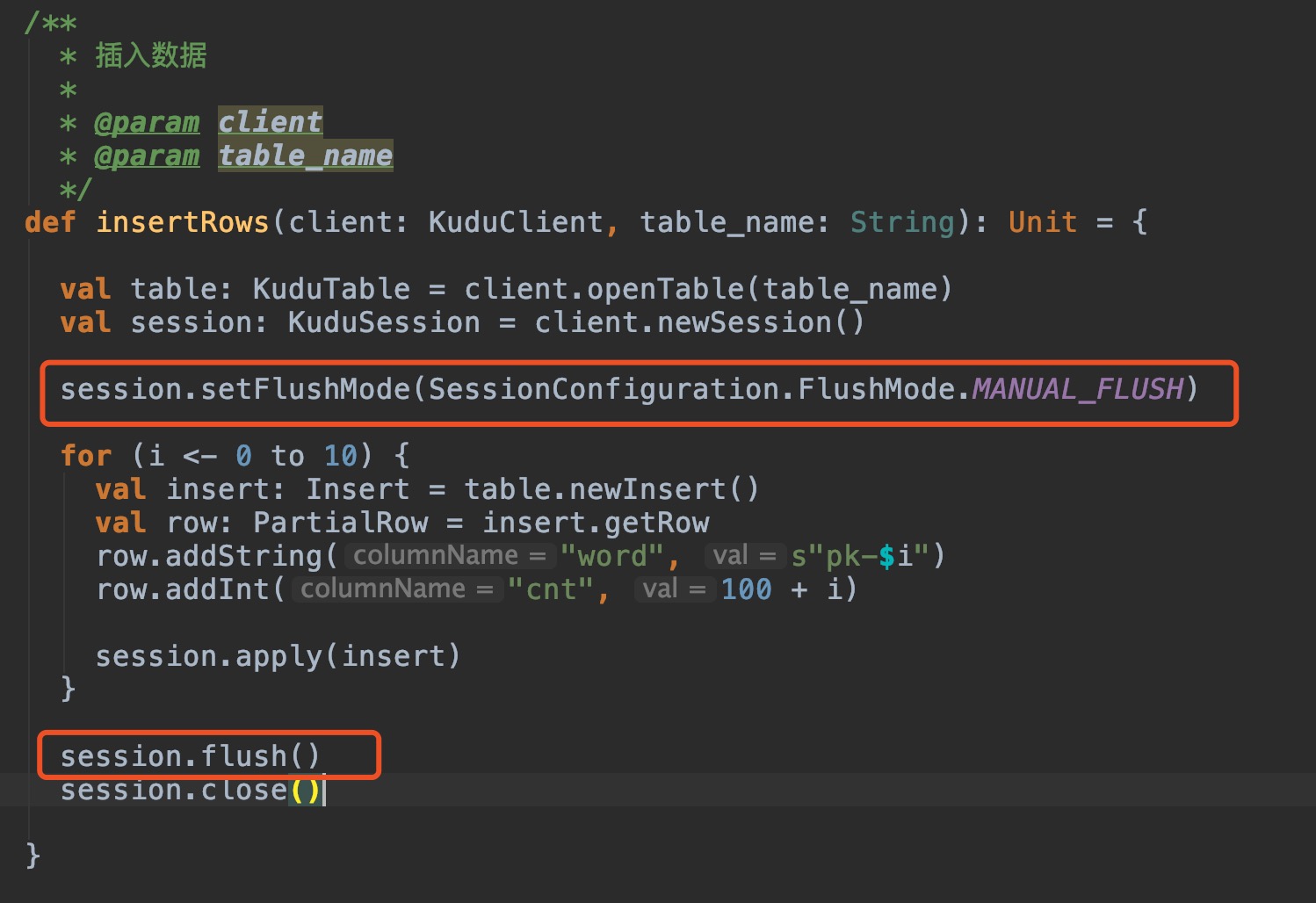
在网上搜了些资料,kudu的批量插入执行,貌似没有特定的方式,是通过将要插入的数据写入内存,然后再批量落入磁盘中的
通过设置FlushMode.MANUAL_FLUSH,来实现批量插入
数据会先写到缓存区,在调用session.flush() 方法后,才会执行写操作
对于缓存区大小的设置,可以在官网找到
可以在/etc/kudu/conf/tserver.gflagfile 文件中设置
–memory_limit_hard_bytes 这个参数 默认是4294967296 单位应该是字节吧
不知道做的对不对,pk老师看见了,还烦请批下作业
1133
收起
正在回答
1回答
相似问题
批量插入作业
1184
0
2


批量添加
1361
0
6


如何批量插入答案?
1307
0
2


Mysql 批量插入 大概11W的数据
1297
2
3


老师,mysql插入操作,依赖配置优化 能举个栗子 透露一下吗 有点好奇
1667
13
6


登录后可查看更多问答,登录/注册









