我在debug的时候 停止了 ,求助!!
-- coding: utf-8 --
import re
import scrapy
import json
try:
import urlparse as parse #python 2
except:
from urllib import parse #python 3 兼容的方式 2 不行就3
class ZhihuSpider(scrapy.Spider):
name = 'zhihu’
allowed_domains = [‘www.zhihu.com’]
start_urls = [‘http://www.zhihu.com/’]
headers = {
"HOST": "www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:51.0) Gecko/20100101 Firefox/51.0"
}
def parse(self, response):
"""
提取html页面的所有url,并根据这些url进一步爬取
如果提取的url格式为/question/xxx 就下载之后直接进入解析函数
"""
all_urls = response.css("a::attr(href)").extract()
all_urls = [parse.urljoin(response.url, url) for url in all_urls]
for url in all_urls:
pass
def parse_detail(self, response):
pass
def start_requests(self):
return [scrapy.Request('https://www.zhihu.com/signup?next=%2F', headers=self.headers, callback=self.login)] #指定回调函数,不然就会默认回到上面的pass
#这个逻辑也就是说首先从登录页面获取数据
def login(self, response):
response_text = response.text
match_obj = re.match('.*name="_xsrf" value="(.*?)"', response_text, re.DOTALL)
xsrf = ''
if match_obj:
xsrf = (match_obj.group(1))
if xsrf:
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf": xsrf,
"phone_num": "15166791288",
"password": "yang97221949",
#"captcha": get_captcha()
}
return [scrapy.FormRequest( #formrequet可以完成表单提交
url= post_url,
formdata= post_data,
headers=self.headers,
callback=self.check_login #不加括号,只调用函数名称 获取值
)]
def check_login(self, respone):
#验证服务器的返回数据判断是否成功
text_json = json.loads(respone.text)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.headers)
控制台出现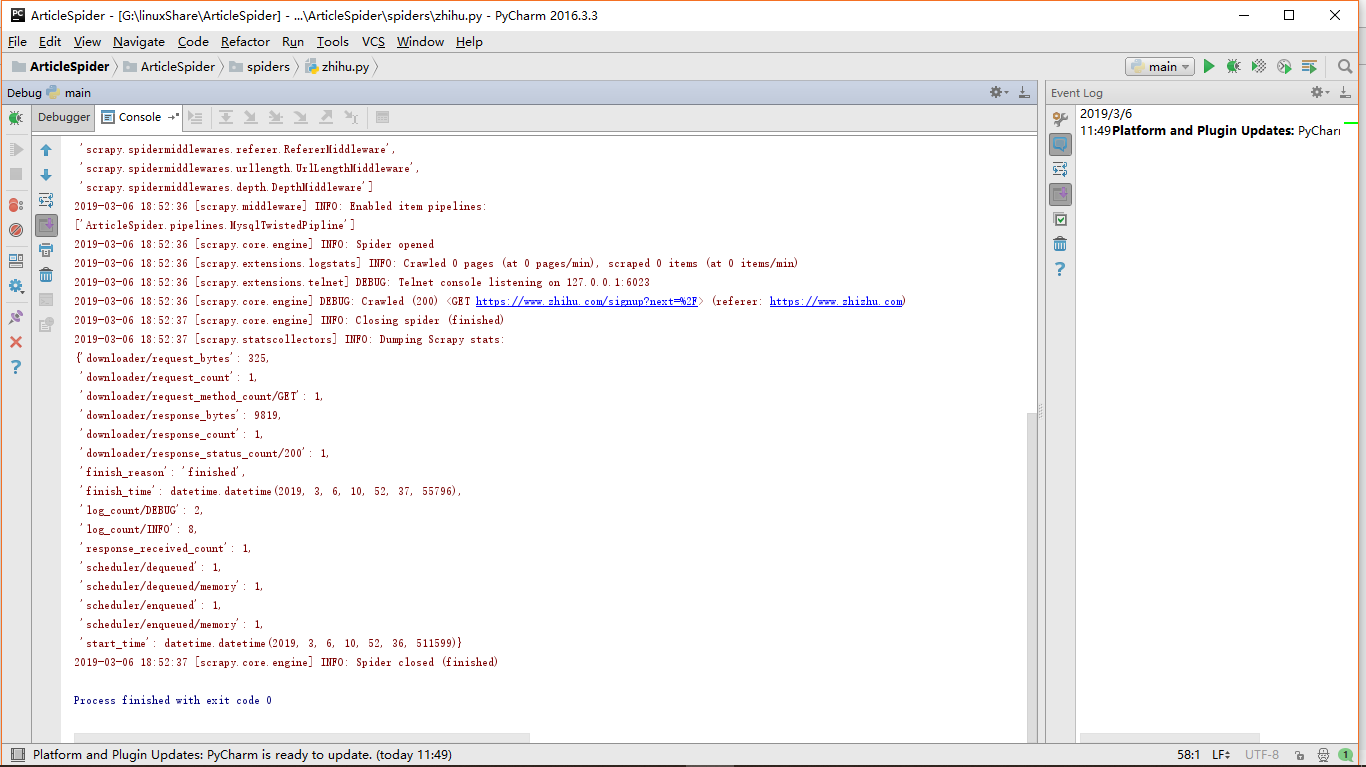
1234
收起
正在回答
1回答

相似问题







登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











