PCA降维后精度下降很多
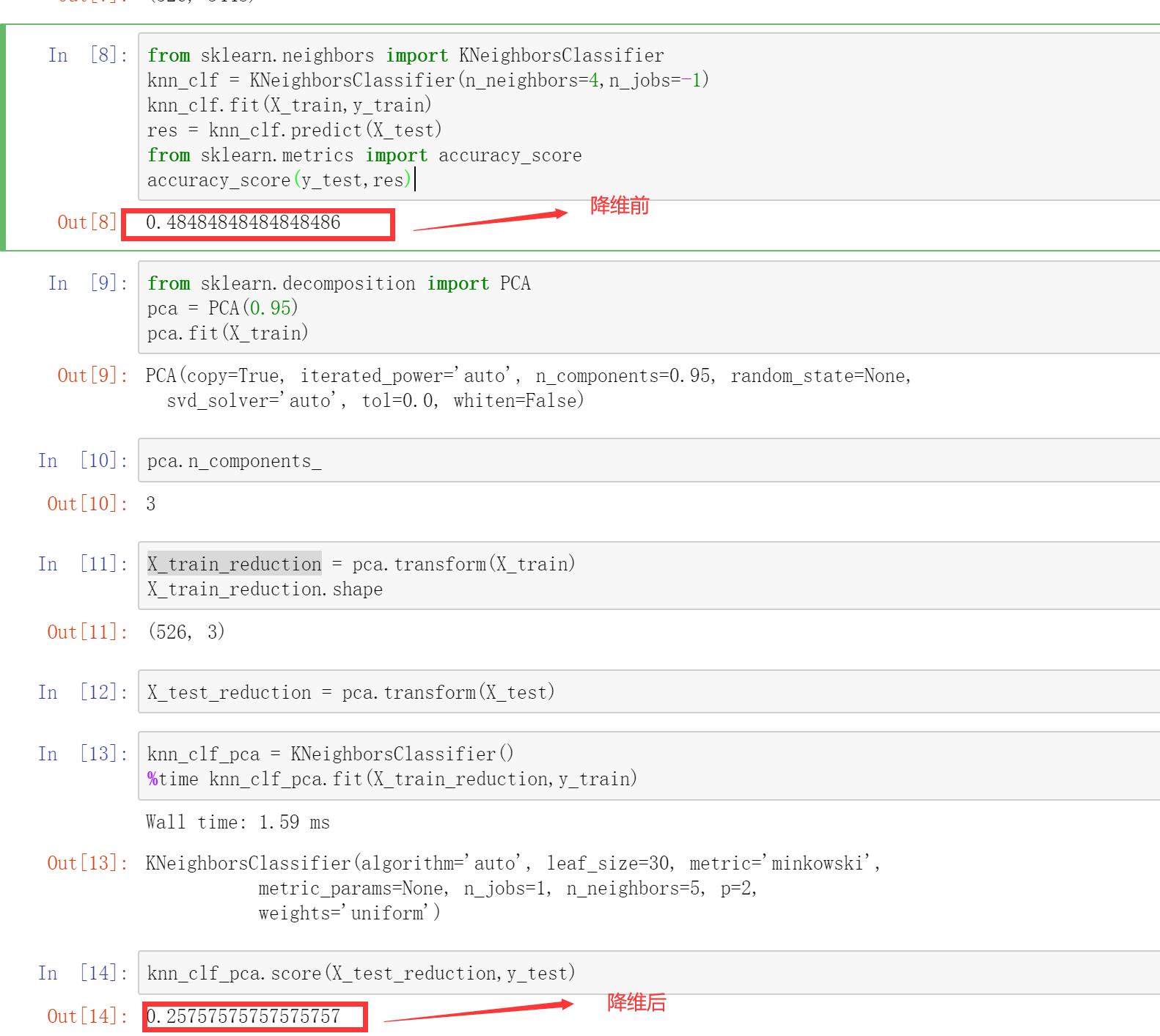
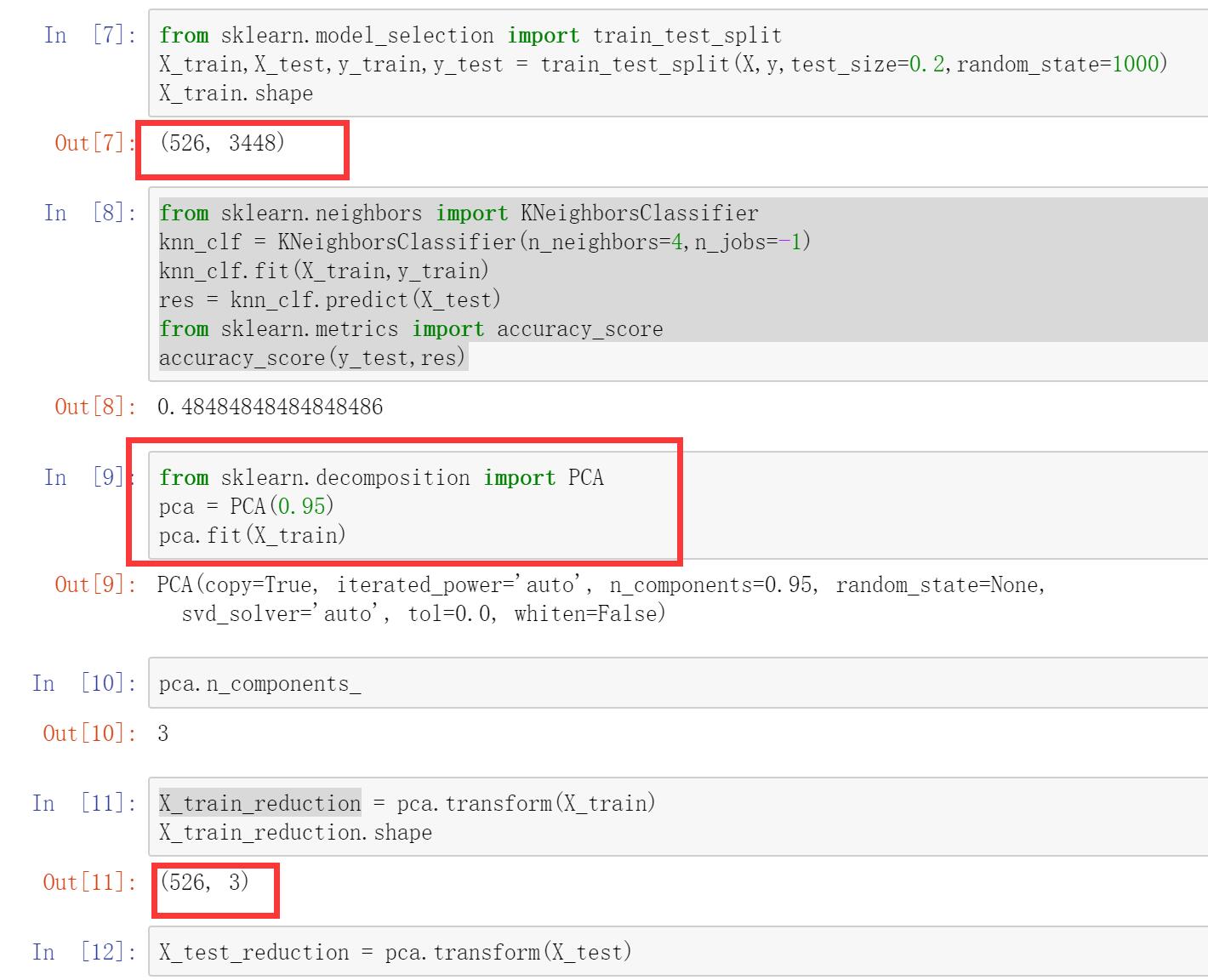
老师你好,我在用PCA做数据降维的时候出现了这种情况,原始数据有3000多个维度,PCA降维设置保留95%信息量,然后降维直接就降到3维,我看了一下数据,数据的各个维度确实相关性很大,然后用降维之后的数据做测试,发现降维后的数据比降维前的数据精度下降了很多,按道理来说不应该降低太多啊,这一般是什么原因呢?我的数据分布如下: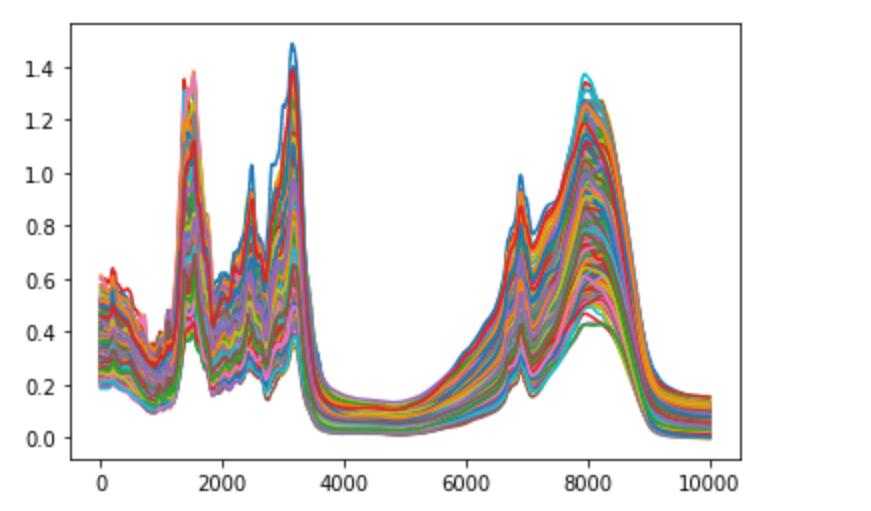

1685
收起
正在回答 回答被采纳积分+3
1回答
相似问题
同等维度PCA的疑惑
1202
0
5


PCA降维的把握和依据分别是什么?比如把一个近似直线分布的二维点数据降维成直线?
3430
6
19


降维处理
1328
0
4
关于PCA的降噪操作有一个地方不理解
1679
0
4
PCA降维的维度问题
2229
3
7
登录后可查看更多问答,登录/注册









{kind=link}