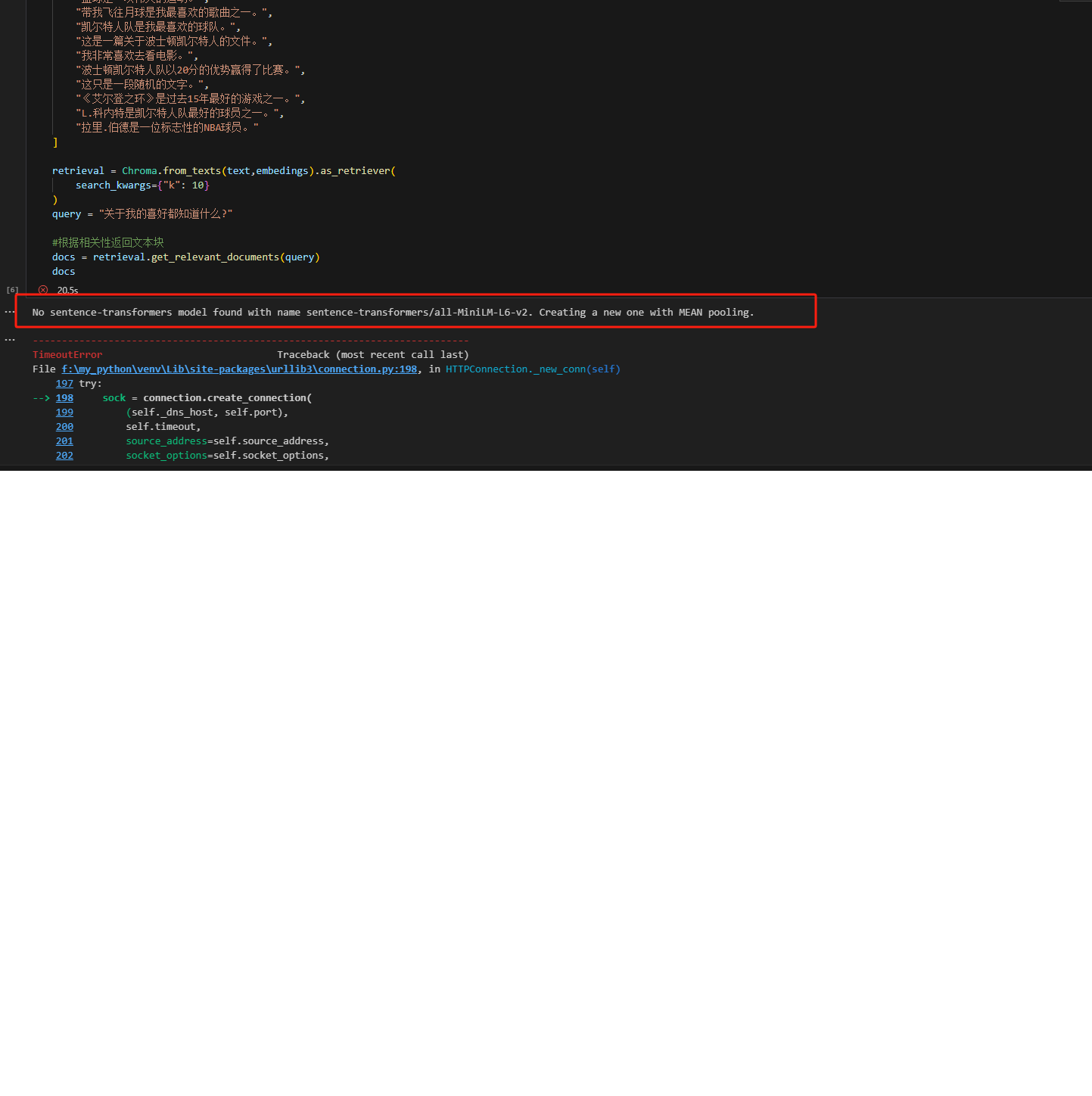
all-MiniLM-L6-v2模型找不到
老师 我已经装了sentence-transformers,但是运行是报找不到all-MiniLM-L6-v2这个模型
3074
收起
正在回答
3回答

相似问题
ollama serve 默认启动哪个模型?
894
0
4


交叉验证训练的模型用哪个呢?
2368
2
9


拿到开源大模型以后还需要去训练吗
1393
0
3
找不到http://127.0.0.1:8880/doc/all
615
0
2




训练数据集就是模型?还是kNN是模型?
2007
2
11


登录后可查看更多问答,登录/注册



