关于二次查找我有点疑问,想确认一下
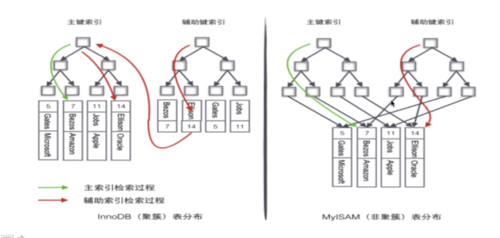
既然innodb辅助索引,要查找二次,那么我是不是认为myisam引擎查询速度要比innodb要快。至少在利用辅助索引来进行查找上面。
如果我的第一点想法没问题的话,那么innob为什么要这么来做,辅助索引的叶子节点为什么不直接存放物理数据的地址。这样不是更快吗?是什么样的原因让它必须这么来二次查找。
782
收起
正在回答 回答被采纳积分+3
1回答

相似问题
延迟消息,进行二次确认,回调检查的相关问题
1873
1
9




关于端点有一个疑问?
908
0
3




老师您好,想咨询您以下几个问题:
1492
0
4




关于7-9的leetcode第二个问题的疑问
1224
0
5




关于绑定逻辑的疑问
1070
0
3


登录后可查看更多问答,登录/注册














